
为什么大多数 AI 应用在生产环境会出问题
大多数 AI 功能一开始都很简单。
你调用模型 API。 你等待响应。 你把结果返回给前端。
“它能跑,直到它突然不能跑。”
一旦 AI 变成真正的产品能力,新的要求就会出现:
- 你需要在展示前验证输出
- 你需要用数据库数据补充结果
- 你需要触发副作用
- 你需要重试与超时
- 你需要可观测性
- 你需要实时更新,但又不能阻塞请求
到了这一步,同步式 AI 调用就不够了。
你需要的是一个系统。
而这个系统需要是事件驱动的。
同步式 AI 的问题
最常见的架构大概是这样:
后端等待 AI。 前端等待后端。 一切都紧耦合在一起。
AI 调用是外部且不可预测的。 你的业务逻辑是内部且有状态的。
把两者当成一个阻塞式请求处理,会天然带来架构摩擦。
什么是事件驱动 AI?
事件驱动 AI 会把 AI 生成与结果交付解耦。
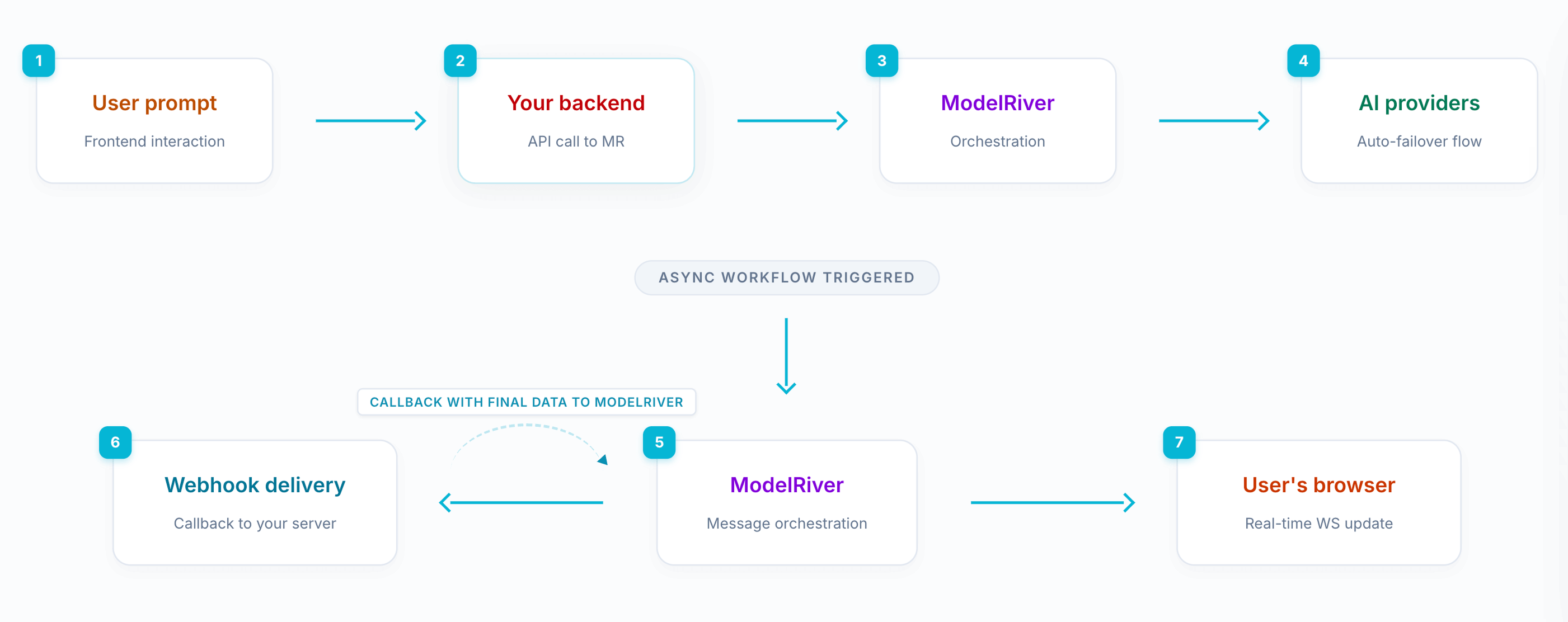
你不再同步等待 AI 响应,而是:
- 发起一个异步请求
- 让 ModelRiver 在后台处理 AI
- 通过 webhook 接收结果
- 运行你自己的后端逻辑
- 通过 callback URL 把增强后的结果发回去
- 将最终结果实时流式推送到前端
整个系统变成了一个生命周期,而不是单次函数调用。
是的,webhook 会引入更多环节。但重试、签名校验和可观测性都由我们来处理。
一个更真实的失败例子
假设 AI 返回了格式错误的 JSON。
你的后端验证结构化输出后拒绝了它。
它不再是:
- 直接让请求崩掉
- 把损坏的数据发给用户
- 让用户一直卡住没有反馈
而会变成这样一个生命周期:
- AI 生成完成
- 后端验证失败
- 后端通过 callback 返回结构化错误
- WebSocket 向用户广播一个友好的错误消息
用户看到的是清晰的失败状态,而不是一个坏掉的 UI。
这就是架构层面的韧性。
事件驱动的三步流程
每一层的职责都非常明确:
- AI 生成
- 后端处理
- 实时交付
它们不再彼此强耦合。
为什么事件驱动架构很重要
天生非阻塞
前端请求不需要等待:
- AI 执行
- 后端处理
- 外部 API 调用
所有步骤都是异步的。
在交付前插入自定义逻辑
你可以完全控制用户最终看到什么:
- 校验
- 补充数据
- 转换
- 存储
- 拒绝
都可以在结果进入 UI 之前完成。
可靠性与重试
事件驱动工作流可以天然支持:
- Webhook 重试
- 超时处理
- 失败可视化
- 安全的 callback 确认
你不需要自己拼复杂的胶水代码,也能获得可靠性。
完整的可观测性
每个步骤都会被记录:
- AI 请求
- Webhook 投递
- 后端 callback
- 最终广播
你不再只能猜测问题卡在了哪一步,而是能准确看到生命周期里哪一环失败了。
什么时候应该继续用同步方式
事件驱动架构很强大,但并不总是必要。
以下场景继续用同步也没问题:
| 场景 | 为什么同步就够了 |
|---|---|
| 原型阶段 | 交付速度比架构更重要 |
| 对延迟极敏感且必须低于 3 秒的流程 | 额外生命周期步骤可能带来额外开销 |
| 简单的 RAG 聊天 | 不需要后端补充处理 |
| 低流量应用 | 复杂度可能还不值得 |
先从简单开始,等生产需求真正出现时再演进。
事件驱动 vs 流式输出 + 后台任务
有些团队会用以下方式来缓解生产问题:
- 直接把 token 流到前端
- 用后台任务做持久化
这确实能解决一部分问题。
但通常会留下不少空白:
- 没有统一的生命周期
- 重试协调更难做
- 可观测性有限
- 失败处理分散
事件驱动架构把以下能力集中在一个地方:
- 执行
- 处理
- 交付
- 可视化
你不是在流式输出之上“补”可靠性,而是把可靠性直接建进整个流程。
更大的架构转变
AI 不只是一次推理调用。
它同时还意味着:
- 工作流编排
- 状态管理
- 外部依赖处理
- 面向成本的执行策略
- 实时分发
当你把 AI 看成一个事件驱动生命周期,而不是一次阻塞式函数调用,系统就会从脆弱变得模块化。
这个转变,正是演示级 AI 和生产级 AI 的分界线。
下一步
- /docs/event-driven-ai
- /docs/webhooks
- /docs/client-sdk
- /docs/observability/timeline
- /docs/observability/timeline
- /docs/api/endpoints
如果你正在生产环境里构建 AI 产品,事件驱动架构能让你获得更强的控制力、可靠性和实时交付能力,同时又不会引入多余复杂度。