

大多数 AI 功能出问题,并不是因为 prompt 写得差
真正的问题往往是:你直接把模型 API 当成了可上线的生产基础设施。
在开发环境里,最顺利的路径看起来很完整。你调用 OpenAI,拿到结果,渲染出来,然后心里会觉得:“好,这一块做完了。”
接着,真实用户来了。
某个 provider 开始限流。延迟突然变高。同一个请求不断被重复发送。某一次响应格式稍微变了一点,你的解析逻辑就崩了。再接着,某个晚上出了问题,你盯着日志开始反复问自己:到底是我们的代码有问题,provider 有问题,网络有问题,还是刚好撞上了某个奇怪的响应?
在 ModelRiver 出现之前,我在做 AI 产品时反复遇到的就是这类问题。一开始我总把它们当成一次性的 bug。多加一次重试,多打一行日志,再补一个解析分支。后来才不得不承认:真正反复出问题的,通常不是 prompt,而是 prompt 周围那层架构。
这些失败模式,其实非常可预测
一个 AI 功能一旦从 demo 阶段进入真实流量,通常很快就会遇到四类问题:
- Provider 故障。你的应用绑在一个 provider 上,所以对方的事故很快就会变成你的事故。
- 重复成本。同样的请求一遍又一遍进来,而你每次都要重新付一遍 Token 成本。
- 缺少可见性。请求失败了,但你很难快速知道到底是哪段 payload、哪次重试、哪条 fallback 链路出了问题。
- 响应契约不稳定。不同 provider 不一样,不同模型也不一样。测试时还能工作的解析逻辑,到生产环境里就开始随机出错。
这不是边缘情况。这几乎就是“直接从应用代码调用单一 provider”之后最自然会出现的结果。
我们在做这个之前,先试过什么
我们并不是一开始就想清楚了“应该做一个抽象层”。如果真是这样,那只能说明我们当时比实际更聪明。
我们先试的是所有人都会先试的方案:在应用代码里自己补重试逻辑,发现某个 provider 状态不稳定时手动切换,打一些临时日志,再在解析层多加几个 if 去兼容输出格式波动。这里补一个 timeout,那里加一个 fallback 标记,再在 parser 里多写一个分支,因为某个 provider 这周返回的字段和上周稍微不一样了。
这些东西多少有点帮助,但也让整个集成越来越难维护。基础设施层面的问题,开始在代码库里到处被零散地解决。到最后,大家都不太想碰那段重试逻辑了,因为它已经慢慢长成了一团谁都不想承担风险的边界情况集合。
真正的问题,是耦合太紧
大多数 AI 应用一开始的架构都很像这样:
做原型时,这完全没问题。但一旦进入生产环境,它会变得很脆弱,因为一切都耦合在同一个外部系统上:
- provider 可用性
- provider 延迟
- provider 响应格式
- provider 定价
- provider 自己的调试工具链
真正缺的是一层位于你的应用和 AI provider 之间的中间层。
这个模式:AI 路由层
更稳妥的做法,是在应用和底层模型之间加上一层 AI 路由层。
这一层负责处理:
- Routing:请求应该发到哪个 provider、哪个模型
- Failover:主 provider 超时或失败时自动切换
- Caching:相同请求不再重复消耗 Token
- Observability:每一个请求都可追踪
- Response contracts:下游拿到的是经过校验的结构化响应,而不是一段“希望它能被解析”的文本
这就是 “demo 能跑” 和 “这个东西我敢上线然后去睡觉” 之间的差别。
代码里到底是什么样
如果你的应用本来就在用 OpenAI SDK,接入改动其实可以非常小。
之前
之后
你的 prompts 不用改。消息格式不用改。流式逻辑和响应解析逻辑也可以保持不变。真正变化的主要只有三点:
base_url指向 ModelRiverapi_key换成 ModelRiver 的 keymodel不再是某个 provider 的原始模型名,而是一个 workflow 名称
这一套方式同样适用于 Python OpenAI SDK、Node.js OpenAI SDK、LangChain、LlamaIndex 以及 Vercel AI SDK。
这基本就是 ModelRiver 的核心:一个兼容 OpenAI 的 AI 路由层,而 workflow 是控制单位。你在控制台里配置 provider、模型、备用链路、缓存窗口和响应契约;你的应用继续调用同一个接口。说实话,刚开始做的时候,我们以为这种分离只是“看起来更优雅”。后来才发现,它几乎就是让生产环境变得可控的关键。
在实际里会发生什么变化
不需要自己维护重试胶水代码的自动故障转移
当主 provider 开始返回 429 或直接超时时,请求不会直接变成用户看到的错误,而是继续尝试下一个已配置好的备用模型。用户拿到的依然是结果,而不是报错。你第二天再看日志时,就能清楚知道到底发生了什么。

我知道这听起来像个小细节。但第一次你需要在生产配置里手动做 failover 决策时,它就不会再显得“小”了。fallback 逻辑是那种团队迟早都会自己在应用代码里重复实现一遍的东西,直到大家都被维护烦为止。我们就是烦透了。
用精确匹配缓存处理重复请求
不是所有请求都适合缓存,但有些请求显然值得缓存。
如果同一个请求被重复发送,ModelRiver 可以直接返回缓存结果,而不是再次打到 provider。这样带来的就是更低的成本和更低的延迟。
关键点在于:这不是模糊缓存,而是 精确匹配缓存。prompts、system messages 和模型设置都必须完全一致。只要不一致,请求就会绕过缓存,按正常流程执行。
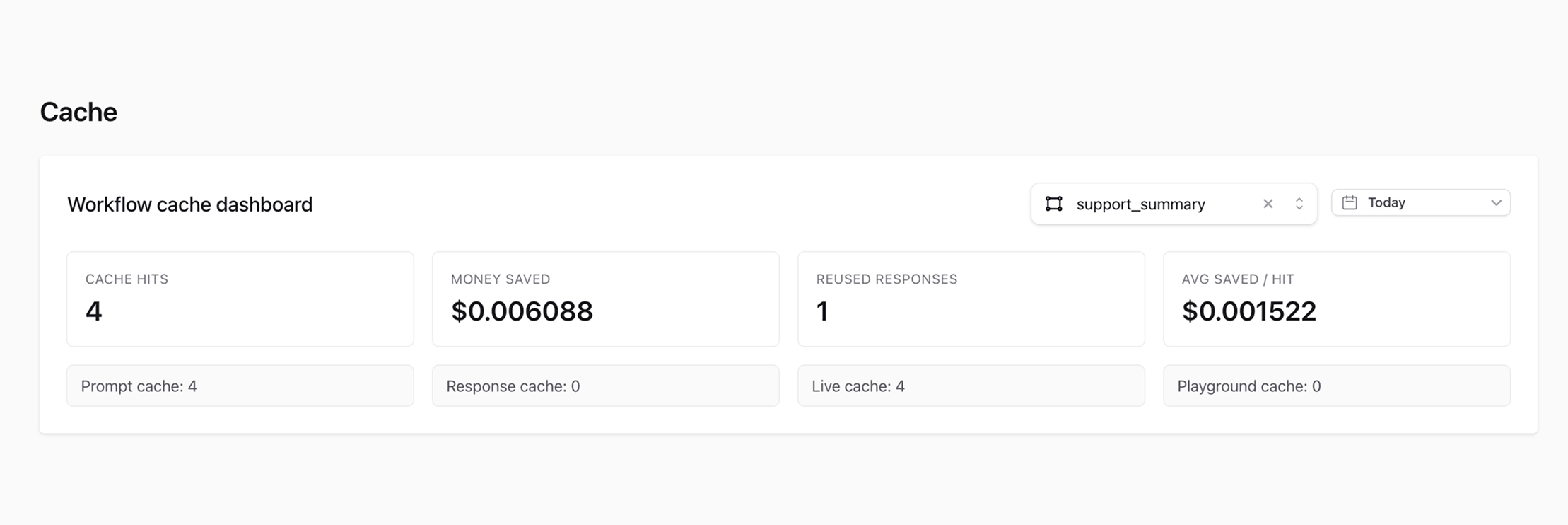
这会让行为变得“无聊”,而这种无聊恰恰是好事。因为当输出结果要进入产品代码时,你最不想看到的就是不确定性。说到底,缓存这一层的意义就是:别再为同一个答案反复付费。
真正能拿来排查问题的可观测性
AI 生产问题里,最糟的未必总是彻底失败的请求。有时候更烦的是:以前 2 秒就能返回的请求,现在突然变成 8 秒;或者某条代码路径不小心在循环里重复调用 provider,一周下来成本悄悄翻倍。我们两种情况都遇到过。
这类问题通常都藏在你的应用和 provider 之间的某一段链路里,而且经常没有一个单一入口可以直接看清楚。
请求日志的价值就在这里。你能直接看到:
- 最终由哪个 provider 处理了请求
- 请求耗时
- 是否触发了 fallback
- token 使用量和成本
- 原始请求体与响应体
在这套东西出现之前,排查一次生产环境里的 AI 问题,往往意味着你要来回看应用日志、provider dashboard,最后还得带着猜测下判断。现在你打开一条日志,整个生命周期都在那里。它不是一个多么“革命性”的想法,只是事实证明,大多数团队并不想自己从头造一遍,包括我们自己。
用响应契约替代“希望它能被解析”
让 AI 功能变脆弱的最简单方式之一,就是因为测试时 JSON 看起来还行,就默认 provider 返回的一定是可信结构。
更稳妥的方式,是先定义一次响应契约,然后让每次响应都经过校验。
在 ModelRiver 里,这件事是通过 structured outputs 配置的。但真正重要的并不是这个 UI 名字,而是架构上的意义:你的前后端依赖的是一个经过验证的 schema,而不是一段自由格式的文本。

这会让你的应用接口在底层 provider 变化时依然保持稳定,整个系统的“心态”也会平静很多。你不会再继续写那种其实偷偷依赖某个模型怪癖的代码。
不需要 redeploy 的控制能力
这是那种一开始很容易被低估、后来却会经常用到的能力。
你可以直接把一个 workflow 切到另一个模型、加一个 backup provider,或者换成更严格的响应契约,而不需要改集成代码。应用仍然调用同一个 workflow 名称,真正变化的是下面那层路由逻辑。
这比把各种 provider 假设散落在代码库里健康得多。它也意味着像“把这个 workflow 切到另一个模型”这种产品决策,不会再自动变成一项工程发布任务。
什么情况下你其实不需要它
有很多场景里,直接调用 provider 仍然是对的:
- 周末项目和原型。你大概率还不需要再加一层。
- 流量很低的应用。如果 uptime 和成本都还不是问题,就先保持简单。
- Provider 特有能力。有些 OpenAI 参数在兼容层里不会被完整传递,比如
logprobs不会被透传,而n > 1会被明确拒绝。 - 后端管道异步工作流。如果你需要 webhook 和 callback 编排,就直接使用原生的 ModelRiver async flow,而不是兼容层 endpoint。
它应该是生产阶段的工具,而不是一个必须从第一天就引入的抽象层。
更大的变化
真正变的并不是代码,而是我们对这个问题的看法。
很长一段时间里,我总把 AI 集成看成一种“特殊情况” - 和数据库不一样,和普通 API 也不一样,因为它输出不确定、失败模式也看起来更怪。但后来我意识到,它并没有那么特殊。它本质上还是“依赖外部服务并在规模下运行”会遇到的那些老问题:可用性、延迟、成本、响应格式、调试。
当我不再把 AI 调用当成某种“魔法能力”,而是开始把它当作基础设施来处理时,很多设计决策一下子就简单了。
如果你现在正处在这个阶段
如果你的 AI 功能已经能在开发环境里工作,但你也开始遇到“为什么它又坏了”的生产版问题,那这个模式值得你认真看看。我们也是在这个阶段,才从打补丁转向真正去做这层基础设施。
你可以从这些文档开始:
接入只需要几分钟。整件事的核心也很简单:你不应该只是因为真实用户来了,就被迫重写半套 AI 集成逻辑。