

Most AI features do not fail because the prompt is bad
They fail because a direct model API call is not enough infrastructure for production.
In development, the happy path feels deceptively complete. You call OpenAI, get a response, render it and think, "okay, this part is done."
Then real users show up.
One provider starts rate-limiting. Latency spikes. The same request gets sent again and again. A response comes back in a slightly different shape and your parser breaks. Something fails late at night and now you are staring at logs trying to figure out: is the bug in our code, the provider, the network, or just this one weird response?
I ran into this pattern over and over while shipping AI-powered products before ModelRiver existed. The first few times, I kept treating each failure as a one-off. Another retry. Another log line. Another parser condition. It took an embarrassingly long time to admit that the prompt was rarely the real problem. The architecture around the prompt was. That was the part that kept biting us.
The failure modes are boringly predictable
Once an AI feature moves from demo traffic to real traffic, four problems show up quickly:
- Provider outages. Your app depends on one provider, so their incident becomes your incident.
- Repeated costs. The same request comes in over and over and you pay full token cost every time.
- No visibility. A request fails, but you cannot easily see the payload, latency breakdown, retry chain, or fallback path.
- Unstable response contracts. Providers differ, models differ and parsing logic that worked in testing starts breaking in production.
These are not edge cases. They are the normal result of calling one provider directly from application code.
What we tried before building this
We did not wake up one day and decide to build an abstraction layer. That would imply we were smarter than we actually were.
We tried the obvious fixes first. Custom retry logic in app code. Manual provider switching when something looked unhealthy. Ad hoc logging. Extra conditionals in the parser to tolerate format drift. A timeout here, a fallback flag there, one more branch in the parser because a provider returned something slightly different than last week. At one point we had a Slack bot that pinged us when latency crossed 5 seconds, which mostly just taught us how often latency crosses 5 seconds.
All of that helped a little but it also made the integration code genuinely unpleasant to work in. Infrastructure problems were getting solved in random places, and nobody wanted to touch the retry logic anymore because it had grown into this fragile nest of edge cases.
The real problem is tight coupling
Most AI apps start with an architecture that looks like this:
That is fine for a prototype. It becomes fragile in production because everything is coupled to one external system:
- provider availability
- provider latency
- provider response format
- provider pricing
- provider-specific debugging tools
What is missing is a layer between your app and the providers.
The pattern: an AI routing layer
The clean way to solve this is to add an AI routing layer between your app and the underlying models.
That layer is responsible for:
- Routing requests to the right provider and model
- Failover when the primary provider fails or times out
- Caching identical requests so repeated traffic does not keep burning tokens
- Observability so every request is traceable
- Response contracts so downstream code gets validated JSON instead of unpredictable text blobs
That is the difference between "the demo works" and "I can ship this and go to sleep."
What this looks like in code
If your app already uses the OpenAI SDK, the integration change can be very small.
Before
After
Your prompts do not change. Your messages do not change. Your streaming logic and response parsing can stay the same. The main difference is:
base_urlnow points to ModelRiverapi_keyis your ModelRiver keymodelmaps to a workflow name instead of a raw provider model
That same pattern works with the Python OpenAI SDK, Node.js OpenAI SDK, LangChain, LlamaIndex and the Vercel AI SDK.
This is what ModelRiver is: an OpenAI-compatible routing layer where a workflow becomes the unit of control. You configure the provider, model, backups, cache window and response contract in the dashboard. Your app keeps calling the same interface. Honestly, the separation seemed like a nice-to-have when we started. It turned out to be the thing that actually made production manageable.
What changes in practice
Auto-failover without custom retry glue
Your primary provider starts returning 429 or timing out. Instead of shipping an error to the user, the request moves to the next configured backup model. The user gets a response. You find out in the morning instead of during the incident.

I know this sounds like a small detail. It stops feeling small the first time you have to make manual failover decisions in a production config. Fallback logic is one of those things teams keep re-implementing in app code until they get tired of maintaining it. We got tired.
Exact-match caching for repeated requests
Not every request should be cached, but some absolutely should.
If the same request is sent repeatedly, ModelRiver can serve the cached response instead of hitting the provider again. That means lower cost and much lower latency on repeated traffic.
The important detail is that this is exact-match caching, not fuzzy caching. Prompts, system messages and model settings must match exactly. If they do not, the request bypasses the cache and runs normally.
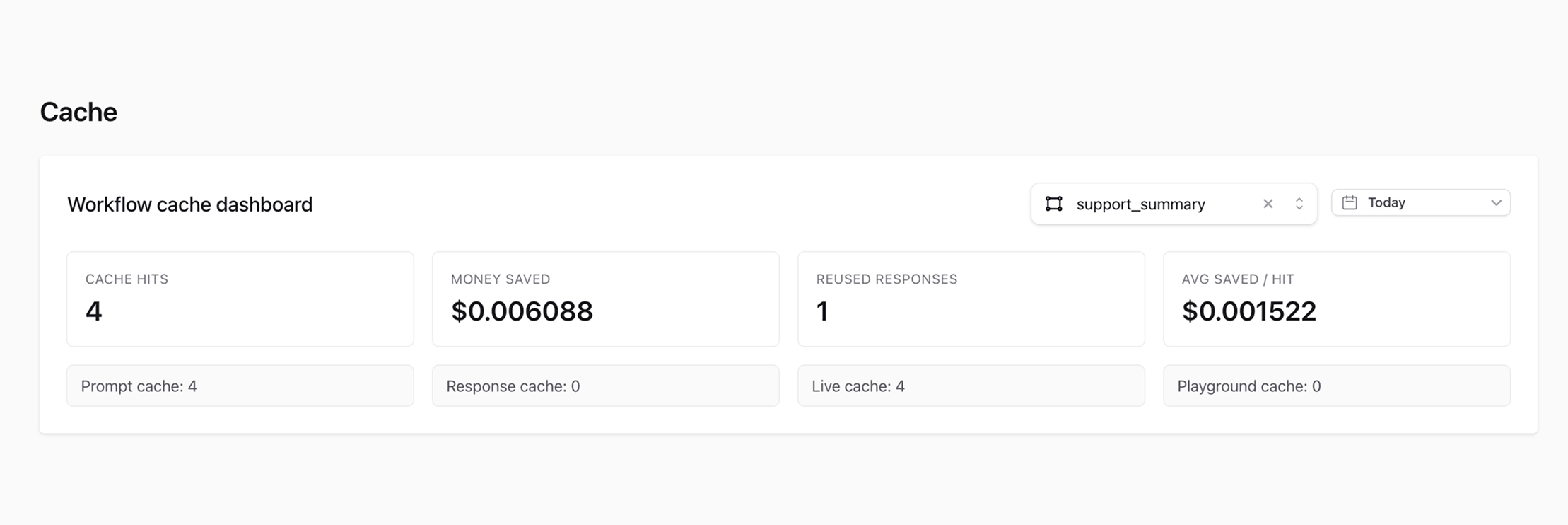
That makes the behavior boring in the best possible way, which is exactly what you want when the output feeds product code. The whole point is to stop paying for the same answer over and over.
Observability you can actually debug with
The worst AI production issues are not always the outright failures. Sometimes it is the request that used to take 2 seconds and now takes 8 and nobody can explain why. Or the one where costs quietly doubled over a week because a code path was hitting the provider with the same prompt in a loop. We have had both.
When that happens, the problem is usually hiding somewhere in the path between your app and the provider, and there is no single place to look.
Request logs fix that by showing:
- which provider handled the request
- how long it took
- whether a fallback was triggered
- token usage and cost
- the raw request and response bodies
Before we had this, debugging a production AI issue meant checking application logs, provider dashboards, and sometimes just guessing. Now you open one log and the whole lifecycle is there. It is not a revolutionary idea. It just turns out nobody wants to build it themselves, including us.
Response contracts instead of parsing hope
One of the easiest ways to make an AI feature brittle is to treat provider output like trustworthy JSON just because it looked good in testing.
A better approach is to define a response contract once and validate every response against it.
In ModelRiver, that contract is configured through structured outputs. The important architectural idea is not the UI label. It is that your frontend and backend now depend on a validated schema instead of free-form text.

That gives your application a stable interface even when the underlying provider changes, which is a much calmer way to build. You stop writing code that is secretly coupled to one model's quirks.
Dashboard control without redeploys
This is one of those benefits people underestimate at first and then end up using constantly.
You can switch a workflow from one model to another, add a backup provider, or attach a stricter response contract without changing integration code. The app keeps calling the same workflow name. The routing layer changes underneath it.
That is a much healthier place to evolve from than scattering provider assumptions across your codebase. It also means product decisions like "switch this workflow to a different model" stop turning into engineering chores.
When you do not need this
There are plenty of cases where a direct provider call is still the right choice:
- Weekend projects and prototypes. You probably do not need another layer yet.
- Very low traffic apps. If uptime and cost are not meaningful concerns, keep it simple.
- Provider-specific features. Some OpenAI parameters like
logprobsare not forwarded through the compatibility layer andn > 1is explicitly rejected. - Event-driven async workflows. If you want webhook and callback orchestration, use the native ModelRiver async flow instead of the compatibility endpoint.
This should be a production tool, not a mandatory abstraction.
The bigger shift
The thing that actually changed was not the code. It was how we thought about the problem.
For a long time I treated AI integration as this special category — different from databases, different from APIs — because the output is nondeterministic and the failure modes feel exotic. But they are not exotic. They are just the normal problems of depending on an external service at scale: availability, latency, cost, response format, debugging.
Once I stopped treating AI calls as magic and started treating them as infrastructure, the design decisions got a lot simpler.
If this is where you are
If your AI feature works in development and you are now running into the production version of "why is this broken again," this pattern is worth looking at. That is exactly the stage where we were when we stopped patching and started building the layer.
You can get started with:
- OpenAI compatibility
- Workflow caching
- Observability and Request Logs
- Structured outputs
- Getting started guide
It takes a few minutes to set up. The pitch is simple: you should not have to rewrite half your integration just because real users showed up.