


为什么开发者需要 ModelRiver?
这篇简短的创始人手记,想尽可能坦诚地回答这个问题。
我们两个人都是技术型创始人。简单说,就是喜欢做工具、也始终贴近新技术变化的开发者。ModelRiver 不是从商业计划书或者市场空白分析表里长出来的,它源于我们在生产环境里交付 AI 产品时,反复踩到的真实问题。
如果你已经知道 ModelRiver 是做什么的,可以直接去看快速上手文档。
如果还不了解,那就从故事的起点说起。
起点
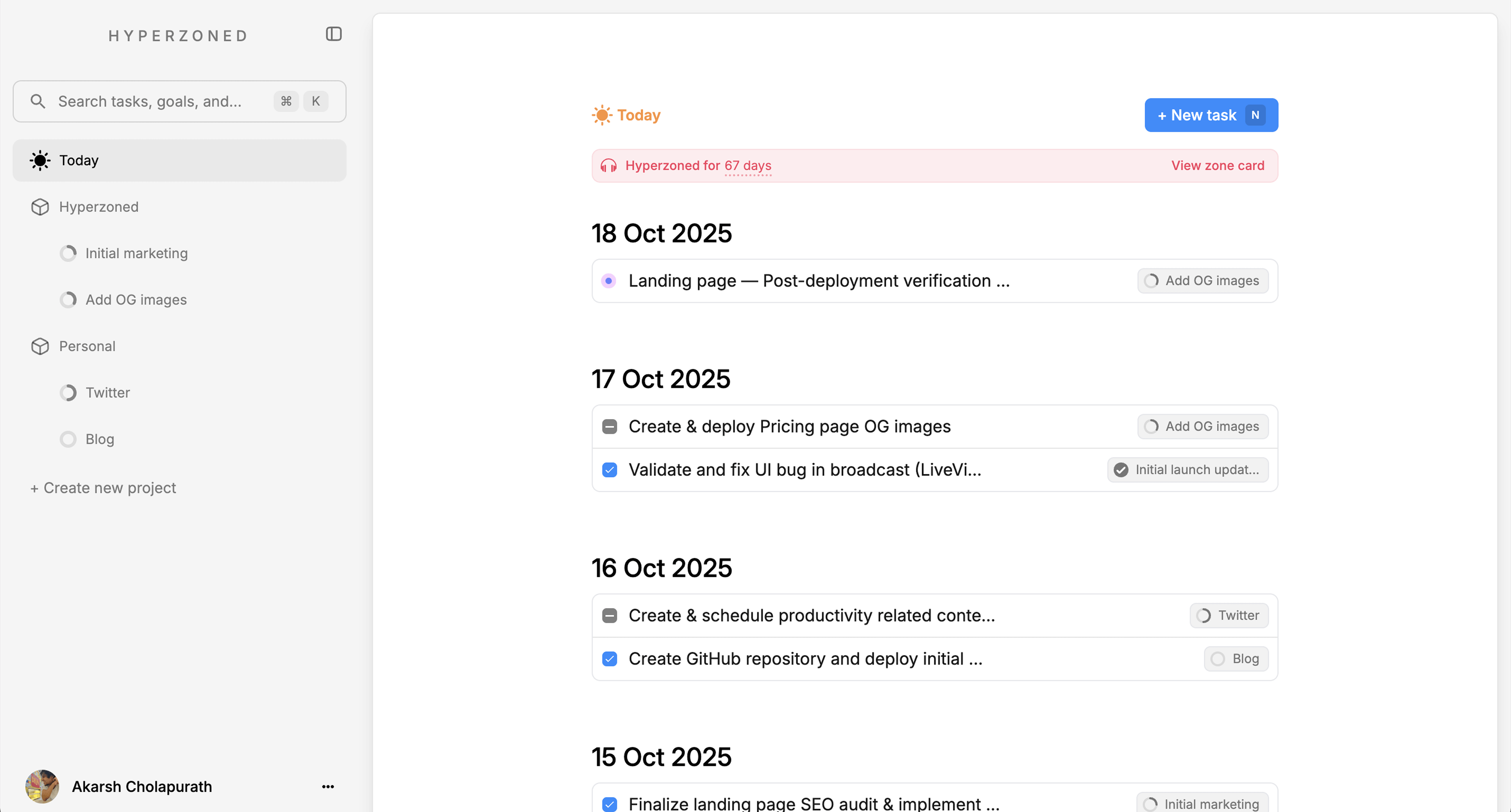
我是 Akarsh。在做另一个产品 Hyperzoned 的时候,我在把 AI 集成进真实应用的过程中,反复遇到几类问题。Hyperzoned 是一个轻量级任务管理和待办应用,支持 AI 辅助创建任务。
Hyperzoned 是个独立项目。核心流程看起来很简单:一个 prompt 生成任务列表。但在实现层面,复杂度很快就冒出来了。
如果一次 AI 请求失败,它会重新请求同一个模型。当时我用的是 Phoenix(Elixir),它依托 BEAM VM 的 “let it crash” 哲学和 Oban 这种持久化后台任务,在容错方面非常强。为了提高可靠性,我还写了自己的模型故障转移逻辑,在一个 provider 宕掉时自动切到另一个模型。
这时另一个问题也越来越明显:每家 AI provider 的输入格式都略有不同,返回结果的结构也不同。想在不同 provider 之间拿到稳定的一致结构化输出,需要写很多胶水代码。
除此之外,Hyperzoned 还必须是实时的。用户应该在无需刷新页面的情况下,马上看到 AI 生成的内容。Phoenix LiveView 和 WebSocket 用很少的基础设施就做到了这一点,也让我意识到一个事件驱动、实时后端的力量有多大。
那段经历让我彻底明白了一件事:AI 周边的基础设施,和模型本身同样重要。
后来我把这个想法告诉了我的朋友 Vishal。他在后端和数据库方面经验很深。我们决定一起原型一个“我们自己也真正想用”的系统。
8 天原型
带着清晰的架构方向,我们在 2025 年 12 月第一周开始构建后来成为 ModelRiver 的东西。
前四天里,我们就已经有了一个可以运行的原型。它不完美,但能工作。我们先用一个小项目做本地验证,快速迭代,同时借助 Claude Code、Codex、Cursor 这些工具加速实验和架构决策。
之后我们把这个原型部署到一台小型 Hetzner 服务器上作为 staging 环境。它在本地表现不错,但到了 staging 和 production,很快就暴露出开发者体验上的不足。
比如:
- Webhook 很难在没有 Ngrok 之类工具的情况下打到 localhost
- 接入流式更新的开发者需要自己从零写 WebSocket 逻辑
- 在排查真实生产故障时,可观测性仍然不够
产品能用,但并不“顺手”。
也正因为这个阶段,我们决定不去发布一个“差不多够用”的东西,而是认真去做我们一直希望存在的 AI 基础设施。
先把开发者体验做好
Client SDK

第一个重要改进,是为 React、Vue、Angular、Svelte 以及 Vanilla JavaScript 构建 Client SDK。
这些 SDK 处理了:
- 自动重连
- 页面刷新后的持久连接
- 基于 WebSocket 的流式更新
开发者不应该每次做 AI 界面时都重复写这一套。
本地开发 CLI

为了改善本地开发体验,我们又做了 ModelRiver CLI。
它允许开发者通过 WebSocket 在本地环境直接接收 webhook,不再依赖额外的隧道服务。你可以用自己的 ModelRiver API key 在本地测试真实工作流,方式和生产环境一致。
可观测性与调试

作为开发者,我们很清楚调试分布式系统有多痛苦。
所以我们重做了可观测性层,去追踪一次请求的完整生命周期:从最初 API 调用开始,经过每一个内部步骤,再回到客户端。没有黑盒。出问题时,你可以精确知道到底是哪一步、因为什么失败。
事件驱动异步请求
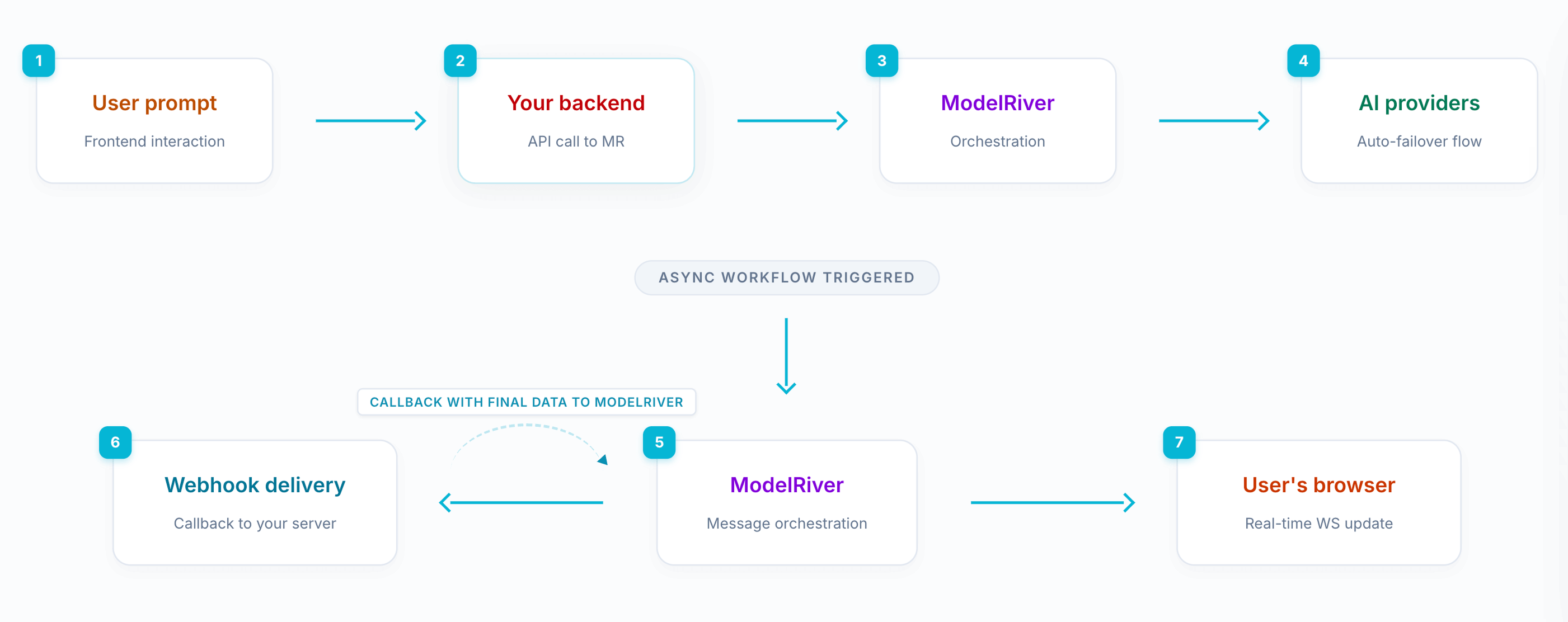
虽然我们一开始就支持异步请求,但后来意识到还缺一块关键能力。
很多应用都需要:
- 先拿到 AI 响应
- 在自己的后端做处理或存储
- 再把结果实时更新到前端
所以我们加入了**事件驱动工作流**。你的后端可以通过 webhook 监听特定事件,对数据做修改和增强,再用 callback URL 把结果发回 ModelRiver。随后 ModelRiver 会把更新后的结果实时推送到前端。
这让你可以在不把系统紧耦合在一起的前提下,构建复杂的实时 AI 工作流。
接下来要做什么?
我们已经打下了一个很强的基础:可靠的基础设施、实时流式更新、可观测性,以及灵活的事件驱动工作流。
我们已经提供了一个完整、可直接用于生产的聊天机器人示例和逐步接入文档。所有配置和集成步骤都可以免费使用,唯一成本来自你的 AI provider 调用费用,而且你完全可以先从低成本模型开始。接下来几周,我们也会持续在这个博客以及 X、Instagram、GitHub 上分享更多指南、更新和示例。
在这之外,我们当前最关注的,是帮助开发者用 ModelRiver 解锁真正有价值的使用场景。我们正在做:
- 视频教程
- 可视化讲解内容
- 公开示例仓库
- 更深入的技术文档
如果你正在生产环境里构建 AI 产品,我们希望 ModelRiver 能像帮助我们一样,帮你节省大量时间和反复试错的成本。