
这个 bug 看起来像是你的 parser 坏了
第一次遇到这种问题时,它很像应用代码的 bug。
我在给 support-ticket 分类器接 fallback provider 时又撞上了这个问题。OpenAI 在 staging 里表现完美。Gemini 的第一条响应在日志里也看起来没问题——直到 validation 失败,工单再也没有进入队列。
你定义了一个 JSON schema。你在一个 provider 上测试过。返回值是合法 JSON,Zod 或 Pydantic parser 也能通过,于是功能上线了。
然后你把同一个 workflow 切到另一个 provider。
模型 API 没有报错。请求日志里看起来也成功了。响应仍然是 JSON。但应用还是坏了,因为返回的数据形状变了。Provider 觉得这个响应可以接受,但你的应用契约不接受。
乍看差不多。严格校验时却足够失败:
priority应该只能是"low"、"medium"、"high"或"urgent"requires_human_review应该是 boolean,不是 string
这就是结构化输出里最容易被低估的点:合法 JSON 不等于合法的应用契约。
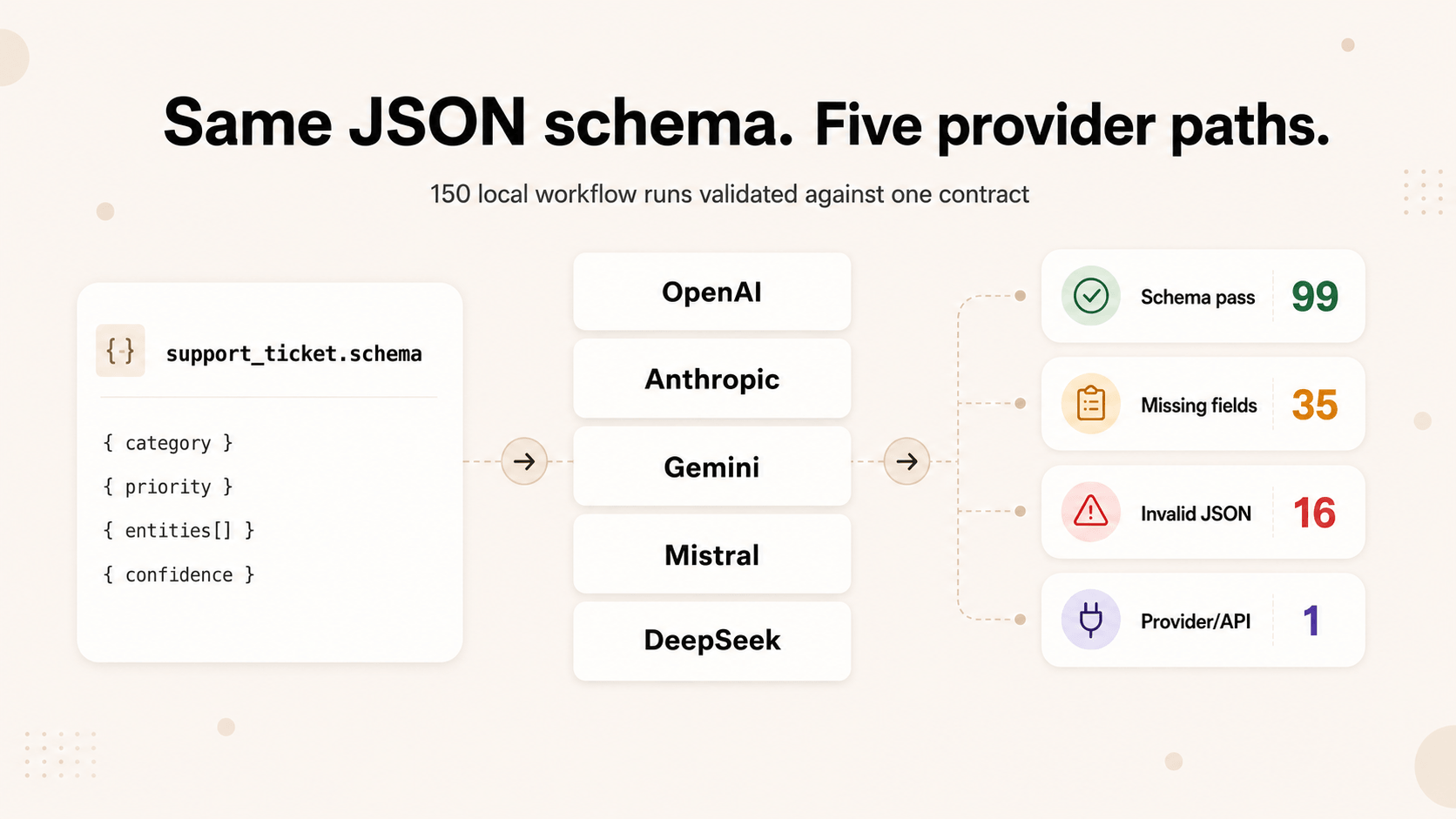
所以我们做了一个小实验——一部分是因为我想要数据,一部分是因为我厌倦了靠猜来判断换 provider 会不会真的撑住。
实验
我们想回答一个很实际的问题:
如果把同一个 JSON schema 和同一组 prompts 发给不同 LLM provider,应用最终拿到的是同一个 contract 吗?
我预料会有一些 drift。没想到三个 provider 次次通过,而另一个 30 次全部失败。
测试设置很简单。
我们测试了五个 provider:
- OpenAI
- Anthropic
- Google Gemini
- Mistral
- DeepSeek
这组测试用了 30 条接近生产环境的 support-ticket prompts。它们都属于同一个分类任务,但覆盖了 AI 应用里常见的抽取和分类问题:
- 账单和 invoice 争议
- API 鉴权失败
- 销售和价格咨询
- 账号删除和数据保留请求
- webhook 失败和重复投递
- structured-output parser bug
- failover 和 provider routing 问题
- 安全、guardrail 和 audit log 问题
每个 provider 收到相同任务、相同 structured-output schema 和相同校验规则。每个响应都用同一个 validator 检查。
这次实验在 2026 年 6 月 25 日 IST,用本地 ModelRiver workflows 跑完。这个细节很重要:这不是直接用各家 vendor SDK 做的 benchmark。它测的是同一个 ModelRiver structured-output workflow contract 通过五个 provider adapter 后,应用实际拿到什么。
这个 caveat 对 Gemini 尤其重要。下面的 0% 不代表“Gemini 总是 structured outputs 失败”。它只表示在这次运行里,这个 schema、prompt set、ModelRiver Google adapter path、model 和 validator 的组合,没有得到任何一次 strict contract-valid output。
| Provider | Workflow | Model | Temperature | Max tokens | Runs |
|---|---|---|---|---|---|
| OpenAI | schema_test_openai | gpt-4.1-mini | 0 | 800 | 30 |
| Anthropic | schema_test_anthropic | claude-sonnet-4-6 | 0 | 800 | 30 |
| Google Gemini | schema_test_gemini | gemini-2.5-flash | 0 | 800 | 30 |
| Mistral AI | schema_test_mistral | mistral-small-latest | 0 | 800 | 30 |
| DeepSeek | schema_test_deepseek | deepseek-v4-flash | 0 | 800 | 30 |
Runner 每次请求之间等待 4.5 秒,避免触发本地 IP rate limit。Schema、prompts、runner、结果 CSV 和汇总文件都在 blog/assets/schema-provider-experiment/。Raw provider responses 没有放进公开 blog assets,因为里面可能包含 adapter/debug 细节,不适合发布。
Schema
我们没有用太玩具的例子,因为玩具 schema 往往隐藏了真正的问题。
这个 schema 包含:
- required strings
- booleans
- numeric confidence scores
- nested objects
- arrays of objects
- enums
additionalProperties: false
简化版本如下:
最终运行时,我们从 confidence 上移除了 minimum 和 maximum,因为 Anthropic 的 native structured-output schema 不接受这些关键字。这本身就是一个提醒:所谓“同一个 schema”,有时必须退到所有 provider 路径都能接受的子集。
这不是一个很奇怪的 schema。很多生产 AI 功能都会需要类似的结构。它只是足够严格,能看出“模型返回了 JSON”和“应用可以安全使用这个响应”之间的差距。
结果
| Provider | Strict schema pass rate | Missing fields | Extra fields | Enum drift | Invalid JSON | Provider/API errors |
|---|---|---|---|---|---|---|
| OpenAI | 100% | 0 | 0 | 0 | 0 | 0 |
| Anthropic | 100% | 0 | 0 | 0 | 0 | 0 |
| Google Gemini | 0% | 14 | 12 | 3 | 16 | 1 |
| Mistral AI | 100% | 0 | 0 | 0 | 0 | 0 |
| DeepSeek | 30% | 21 | 12 | 13 | 0 | 0 |
在有人把 Gemini 那一行截图之前先说清楚:这不是一个通用的 provider 排名。它只是来自一个 schema、一组 prompts、一个 validator、一个 model 版本和一条 ModelRiver adapter path 的报告。其中任何一项换掉,数字都可能改变。
这些 secondary columns 会重叠。比如同一个响应如果返回了完全不同的对象形状,它可能同时算作 missing fields 和 extra fields。
重点不是说某个 provider “好” 或 “坏”。在这次运行里,OpenAI、Anthropic 和 Mistral 都通过了这个 contract。Gemini 没有任何一次通过:多数失败是 malformed JSON 或者返回了另一个对象 contract,另有一次 upstream availability error。DeepSeek 30 次里通过 9 次,但很多时候返回的是简短分类对象,而不是完整应用 contract。
看到 Gemini 是 0% 时,我第一反应是怪我们的 adapter。然后我打开了 raw responses。其中一半看起来像合理的回答,只是不是我们写下的 contract。这种不匹配比干净的 error 更糟——它会安静地失败。
这才是生产里最熟悉的痛点。失败响应并不总是荒谬的。很多回答其实人类能看懂,也挺合理。但它不是应用承诺自己会收到的 shape。
应用代码通常不是因为“provider 质量”这种抽象原因坏掉。它是因为这些具体假设被打破:
- 这个字段一定存在
- 这个值一定是 enum
- 这个 number 真的是 number
- 这个 object 不会多出 key
- 这个 nested array 永远是 array
当这些假设随着 provider 改变时,切模型就不只是 routing change,而是 contract migration。
这个实验不能证明什么
这个测试不能证明某个 provider 在 structured outputs 上永远比另一个好。它只能说明:同一个应用 contract 在不同 provider path 上可能表现不同。
不同的 schema、prompts、model 版本、SDK,或 provider 原生的 structured-output 设置,都可能产生完全不同的结果。在这里拿到 0% 的 provider,换一个更宽松的 schema、不同的 model,或者它自己的 native structured-output 模式,也许就能干净通过。重点不是“这个 provider 不行”,而是“同一个 schema”并不是一个可以不测就依赖的保证。
Failure mode 1: 合法 JSON,但 contract 错了
最危险的失败之一,是日志里看起来没问题,但 runtime validator 失败。
Gemini 在 ticket_007 返回了:
这是合法 JSON。它也是错误 contract。
Schema 要求的是:
Validator error 很直接:
模型给了一个合理标签。应用要的是一个结构化对象。
Failure mode 2: 截断的 JSON
Gemini 在 ticket_001 还返回过 malformed content。下面是 wrapped response payload 的一个 excerpt,候选 JSON 位于 content string 中:
这类问题很烦,因为响应开头看起来像 JSON。如果你的日志只显示前几个字符,看起来模型像是遵守了规则。Parser 会在后面失败。
我曾经被一个这种响应坑了一个下午。日志片段看起来合规。完整 payload 在 invoice ID 半截处被截断了。
这次运行里,Gemini 产生了 16 次 invalid JSON。其中多次是被截断的字符串,也有一些是应用期待 JSON object 时返回了普通文本。
Failure mode 3: 多余字段和 enum drift
DeepSeek 在 ticket_006 返回了:
同样,这是合法 JSON,而且人类能理解。但 schema 不允许 issue 或 severity。category 必须是 lower-case enum 之一,而且响应还缺少 summary、entities、requires_human_review 和 confidence。
DeepSeek 在其他 prompts 里也出现了 enum drift:
这不是随机错误。它是在尝试有帮助。但应用代码不需要有创造力的 enum,它需要自己能处理的值。
Failure mode 4: Provider errors 也是 schema reliability 的一部分
不是所有失败都是模型输出坏了。有些失败发生在可用响应回来之前。
Gemini 在这次运行里有一次 upstream availability error:
如果应用依赖结构化响应,provider error 对应用来说仍然是 contract failure。UI 或 backend 期待一个 typed object,但最后没有 object。
为什么 mock 测试会漏掉这些
很多团队会用 fixture 测 structured outputs。
这有用,但它主要是在测试你自己的代码。它没有测试 provider 行为。
Mock response 很少覆盖:
- enum drift
- required field 里的
null - stringified boolean
- array 被压成 object
- JSON 外面包了一段 prose
- provider-specific schema interpretation
- retry 或 timeout 后的 partial response
测试通过,是因为 fixture 比生产环境更听话。
什么真的有帮助
没有一个 magic flag 能让所有 provider 的 structured outputs 都自动 production-safe。
但有几件事很有用。
每个响应都要校验
不要停在 JSON.parse。
Parseable JSON 只说明语法合法,不说明应用 contract 被遵守。
用 JSON Schema、Zod、Pydantic、Valibot 或任何适合你 stack 的 validator。重点是每个 provider response 都要校验,而不是只在测试里校验。
记录 raw provider output
校验失败时,你需要原始响应。
如果日志里只有 “schema validation failed”,你仍然不知道 provider 是漏了字段、改了 enum、返回了 prose,还是重塑了 nested object。
Raw output 才能帮你区分 prompt 问题、provider quirk 和真正的应用 bug。
按 provider 和 model 追踪失败率
Structured-output reliability 不只是 provider 层面的属性。它会随着 model、prompt、schema complexity 和 output length 改变。
按 provider 和 model 记录 validation failure rate。否则 fallback provider 可能悄悄变成 broken contracts 的来源。
不要把 provider quirks 散落在 app code 里
很容易写出这样的分支:
第一次有效。然后它会到处蔓延。
更干净的模式,是把 provider-specific formatting、validation、retry 和 normalization 放在一个薄 routing layer 后面。产品代码应该消费一个 contract,而不是五种 contract interpretation。
CI 用 deterministic fixtures
Provider calls 昂贵、慢,而且非确定。CI 不应该每次都依赖 live LLM behavior。
用 deterministic sample outputs 测应用 integration path。然后把 provider-compatibility suite 放到定时任务里,或者 workflow 变更前单独跑。
这两种测试解决不同问题:
- fixtures 测你的应用 contract
- provider runs 测真实 model behavior
两者都需要。
自己跑一遍
Prompt set、schema、runner、result CSV 和 aggregate summary 都在:
如果要对外发布实验资产,可以把这个 folder 移到 gist 或小型 public repo。Raw provider responses 建议保持私有,除非每个 payload 都经过人工 review 和 redaction。
最小可用版本大概五分钟:
- 从你的 app 里选一个 structured-output schema。
- 写 10 条接近真实用户输入的 messy prompts。
- 把同一个 schema 和 prompts 发给你依赖的每个 provider。
- 用同一个 validator 校验每个响应。
- 记录 failure shape,而不只是 pass/fail。
如果你已经注册 ModelRiver 但还没真正发过请求,这就是一个很适合的第一个 workflow:定义 schema,挂到 workflow 上,用 Test Mode fixtures 先验证应用 contract,再在 provider keys 配好后做 provider comparison。
为什么我们关心这个问题
这类 bug 我在生产 AI 工作里反复遇到。这也是我们构建 ModelRiver 的重要原因之一。
难点不是让模型偶尔返回一次 JSON。难点是当你切换 provider、加 fallback、debug failures、测试 workflows、检查真实返回值时,contract 仍然稳定。让我印象最深的从来不是那些很显眼的失败,而是响应看起来足够接近、直到客户 workflow 坏掉才有人察觉的那种。
Structured outputs 很有用。但它不是问题的终点。
真正的生产问题,是确保 contract 能走完整条路径:
AI 应用经常就是在这条路径上坏掉的。
这也是为什么 ModelRiver 把 structured outputs 当成一个 workflow reliability 问题,而不只是一个 model-output 问题。你应该能在不同 provider 之间测试同一个 contract,准确看到它在哪里坏掉,并把这些 provider-specific quirks 挡在应用代码之外。如果你想针对自己的 schema 跑一个类似的实验,workflows、validation 和 provider comparison 就是为这件事准备的。