

那个很少有人认真讨论的问题
几乎所有 AI 教程展示的都是最顺利的路径:调用 API,拿到响应,渲染出来,然后发布。
但真正构建 AI 功能时,现实往往是这样的:
你写了集成测试,它们会调用 OpenAI。这意味着每次测试运行都是真金白银。你的 CI 一天跑 20 次?那就是 Token 账单直接乘以 20,而你甚至还没正式上线。
然后是调试循环。你的响应解析逻辑出错了。你改代码、重新调 API、等 3 秒、看响应、发现问题不在这里,再改一次。每一次迭代都要花 Token,还会拖慢反馈速度。你花钱调试的是你自己的代码,甚至还不是 AI 本身。
最糟的是,AI 响应是非确定性的。今天测试通过,明天可能因为模型换了一个说法就失败。CI 无缘无故变红。你重新跑一下又绿了。慢慢地,整个团队都不再相信测试套件。
我们在做 ModelRiver 的过程中就撞上了这堵墙。我们当时在集成多个 AI provider,每一次调试都可能同时烧掉 OpenAI、Anthropic 以及其他 provider 的 Token。成本不只是钱,更是那种持续的不确定感:失败到底是我们的代码、模型,还是网络导致的?
所以我们决定做一个东西,把这个问题正面解决掉。
我们做了什么
我们加了一个功能,叫 Test Mode。
它的想法非常直接:当一个工作流处于 Test Mode 时,它会返回你预先定义的 sample data,结构完全符合应用期望,但不会真正调用 OpenAI、Anthropic 或任何 AI provider。零 Token 消耗,零 AI provider 费用,响应几乎是即时的。
下面是它在实际中的工作方式。
先定义一次你期望的输出
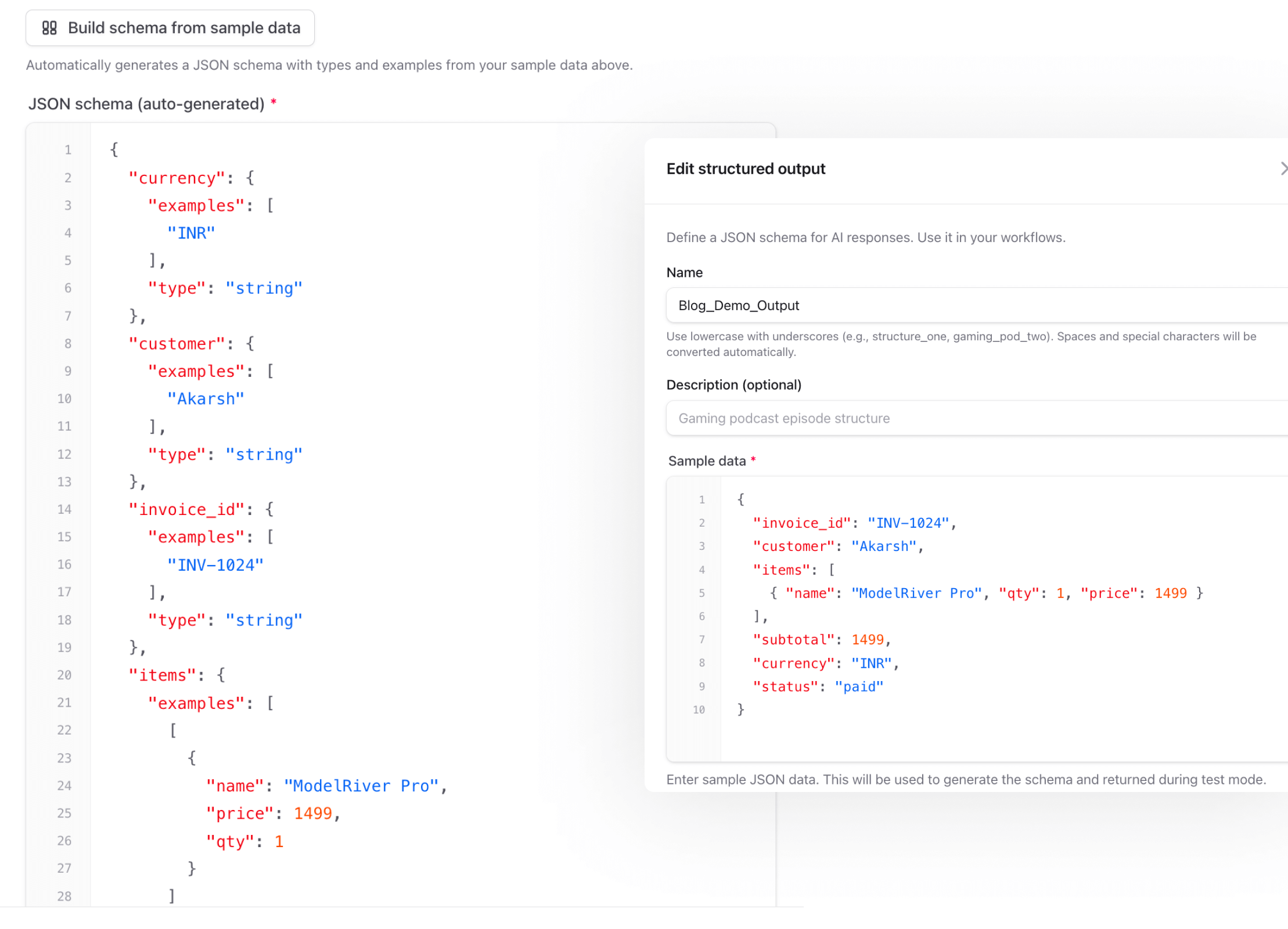
在你的 structured output 配置里,你可以在 JSON schema 的同时提供 sample data。Test Mode 返回的就是这份数据:
这就是它在 ModelRiver 控制台中的样子:左边是 schema,右边是 sample data。
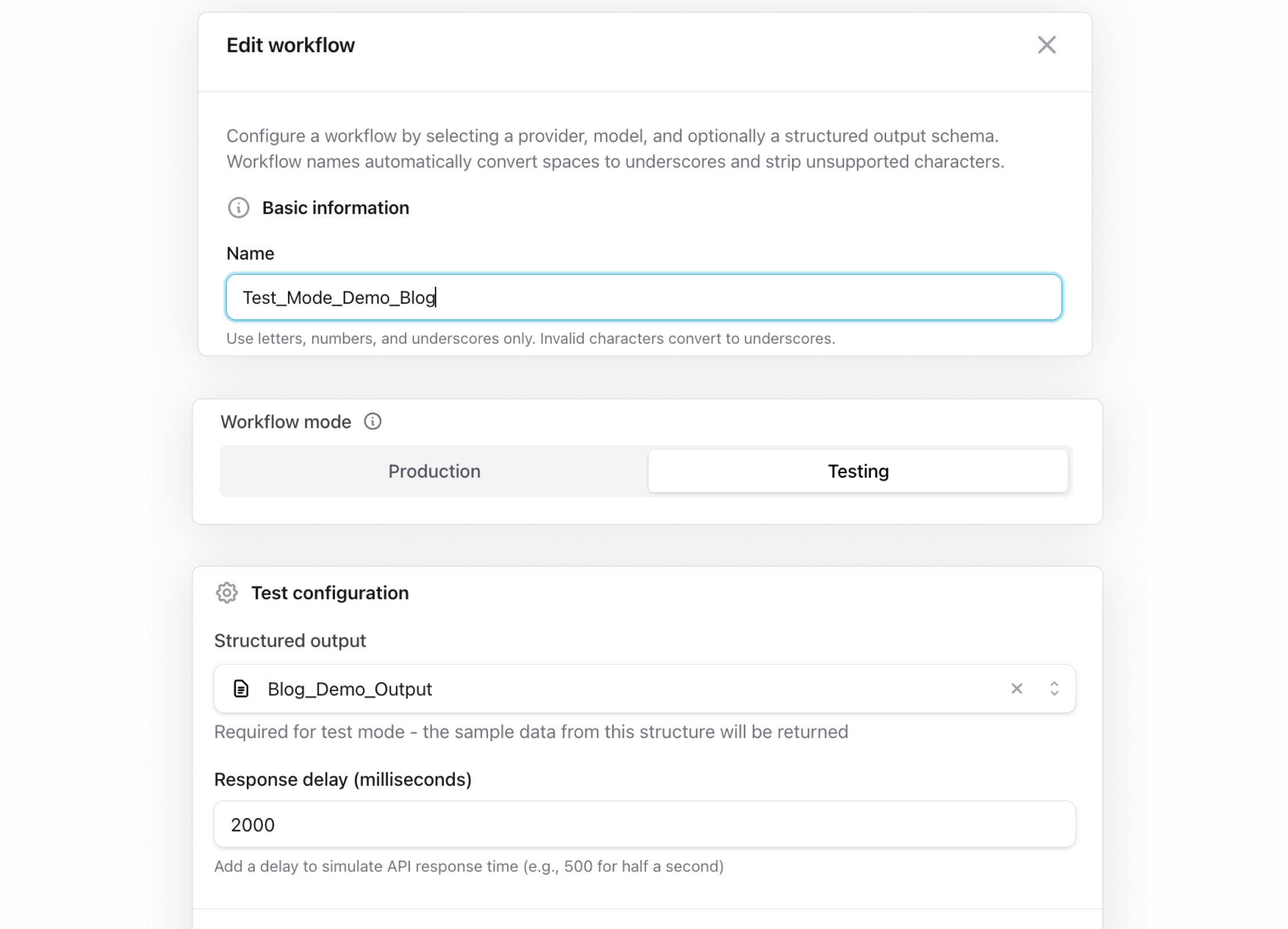
把工作流切到 Test Mode
ModelRiver 中的每个工作流都有一个模式:Production 或 Testing。当切到 Testing 时,这个工作流会直接跳过整个 AI provider pipeline。
你仍然使用自己的 ModelRiver API key,所以认证、请求日志等流程都还是正常运行的;但你不需要配置任何 AI provider 凭证,只需要结构化输出和其中的 sample data。
你的 API 调用完全不用改
代码一点都不用变。还是同一个 endpoint、同一个 payload、同一个 auth:
响应会直接返回你的 sample data:
而这正是 Playground 里的实际结果。你会看到 provider 是 “Testing”,tokens used 是 0:
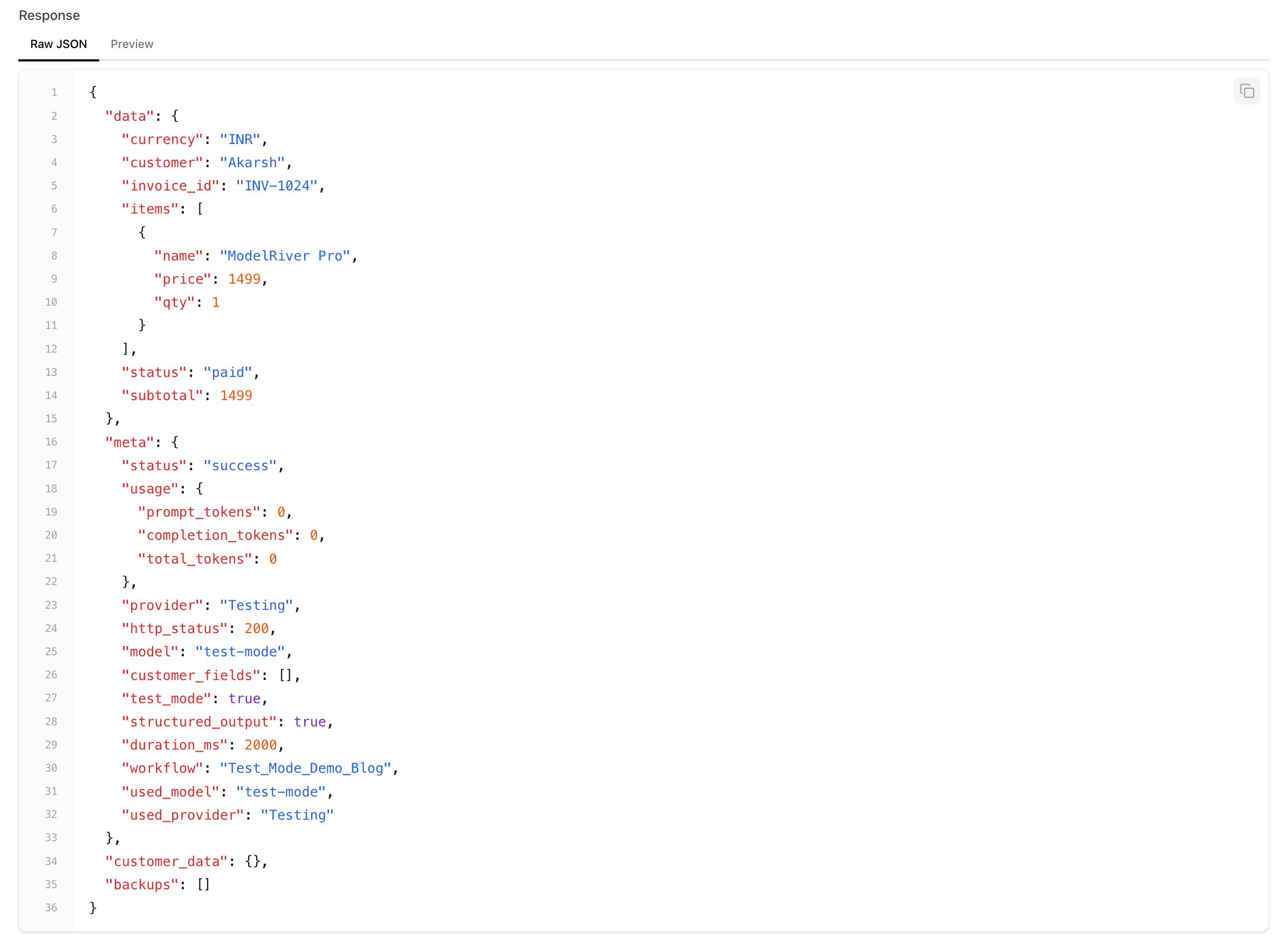
你的应用代码不用变,前端也不用变。返回结构和真实 provider 的响应格式保持一致。唯一不同的是:没有真正调用 AI provider、不会花掉任何 Token,而且你每次都能拿到同样的确定性结果。
这件事为什么真的重要
不烧钱的 CI/CD
我们现在每次 push 都会跑集成测试。在 Test Mode 之前,这通常只有两种选择:要么 mock 整个 AI 层(但这并没有真正测试到真实流程),要么在每次 CI 运行时为真实 API 调用付费。
有了 Test Mode,CI 测试可以直接打到真实的 ModelRiver API,经过真实的认证、路由和响应格式化流程,并拿到稳定可预测的数据。唯一被跳过的是外部 AI provider 调用。除此之外,一切都是真实的。
模拟真实延迟
我们自己早期就踩过一个坑:本地开发时前端 loading state 看起来完全正常,但到了生产环境就显得很卡。原因很简单,真实 GPT-4 调用通常要 2 到 5 秒,而我们之前测试的都是几乎瞬时的响应。
Test Mode 支持配置 response delay。你可以把它设成 2000ms,让工作流在大约 2 秒后返回。这样就能在不花 Token 的前提下,测试 loading、超时和重试逻辑是否真的适用于真实环境。
解耦前端开发节奏
这一点对我们非常关键。前端团队不需要等到 AI pipeline 完全 ready 才能开始做界面。他们可以立刻基于 Test Mode 工作流开始开发。
sample data 本身就是一份契约:“响应结构就是这个,按它来做 UI。” 等 AI pipeline 真正准备好,只要把开关切到 Production,前端代码完全不需要改。
异步和事件驱动工作流也适用
Test Mode 也支持 ModelRiver 的异步 API。你发起一个异步请求,测试响应仍然会沿着相同的 WebSocket 交付链路流转,包括页面刷新后的重连逻辑。如果你还在使用带后端 callback 的事件驱动工作流,这些 callback 也同样会被触发,只不过 payload 是 sample data。
也就是说,你可以在不调用任何 provider 的情况下,完整测试整条实时链路:webhook、callback、WebSocket 推送,全都能跑。
Test Mode 不做什么
也有几个明确的边界:
- 它不会测试你的 prompt。 因为根本没有调用模型,所以你无法用它判断 prompt 质量。Test Mode 测的是你的应用逻辑,不是你的提示词工程。
- 它不会测试 failover。 因为没有 provider 被调用,备用模型链路也不会被走到。这个要在 Production 模式下配低成本模型来验证。
- 响应是静态的。 每次返回的都是同一份 sample data。这正是它的价值所在,但也意味着你不会在这里发现输出波动带来的边缘情况。
更大的背景
Test Mode 只是我们很看重的一件事中的一部分:让 AI 基础设施像数据库、队列和 API 一样可测试、可预测。
现在大多数 AI 集成都还像黑盒。你发出请求,然后祈祷。出了问题,就去看日志,再对着 provider dashboard 猜。我们经历过这一切,所以很清楚这不是一个好的开发者体验。
我们认为这件事可以做得更好。真正的可观测性。真正的测试能力。真正适配 CI 的工作流。把本来属于基础设施工程的严谨性,带到 AI 这一层。
如果你正在构建 AI 功能,也已经受够了为测试运行和调试不断烧 Token,不妨试试 Test Mode。开始使用是免费的,只有当你把工作流切到 Production 时,才会产生 AI provider 成本。
如果你愿意,也欢迎告诉我们你现在是怎么测试 AI 集成的:什么好用,什么痛苦,什么还缺失。我们在 X 上是 @modelriverai,如果你是在 HN 看到这篇,也欢迎直接评论交流。