
The bug looks like your parser is broken
The first time this happens, it feels like an application bug.
I hit it again while wiring fallback providers for a support-ticket classifier. OpenAI looked perfect in staging. The first Gemini response looked fine in the logs too — until validation failed and the ticket never reached the queue.
You define a JSON schema. You test it against one provider. The response is valid JSON, your Zod or Pydantic parser accepts it, and the feature ships.
Then you switch the same workflow to another provider.
No exception from the model API. No obvious provider error. The response is still JSON. But your app breaks because the contract changed in a way the provider considered acceptable and your application did not.
That looks close enough at a glance. It is also enough to fail a strict contract:
prioritywas supposed to be one of"low","medium","high", or"urgent"requires_human_reviewwas supposed to be a boolean, not a string
This is the uncomfortable part of structured outputs: valid JSON is not the same thing as a valid application contract.
So we ran a small experiment — partly because I wanted numbers, and partly because I was tired of guessing whether a provider swap would actually hold.
The experiment
We wanted to test a practical question:
If we send the same JSON schema and the same prompts to different LLM providers, do we get the same contract back?
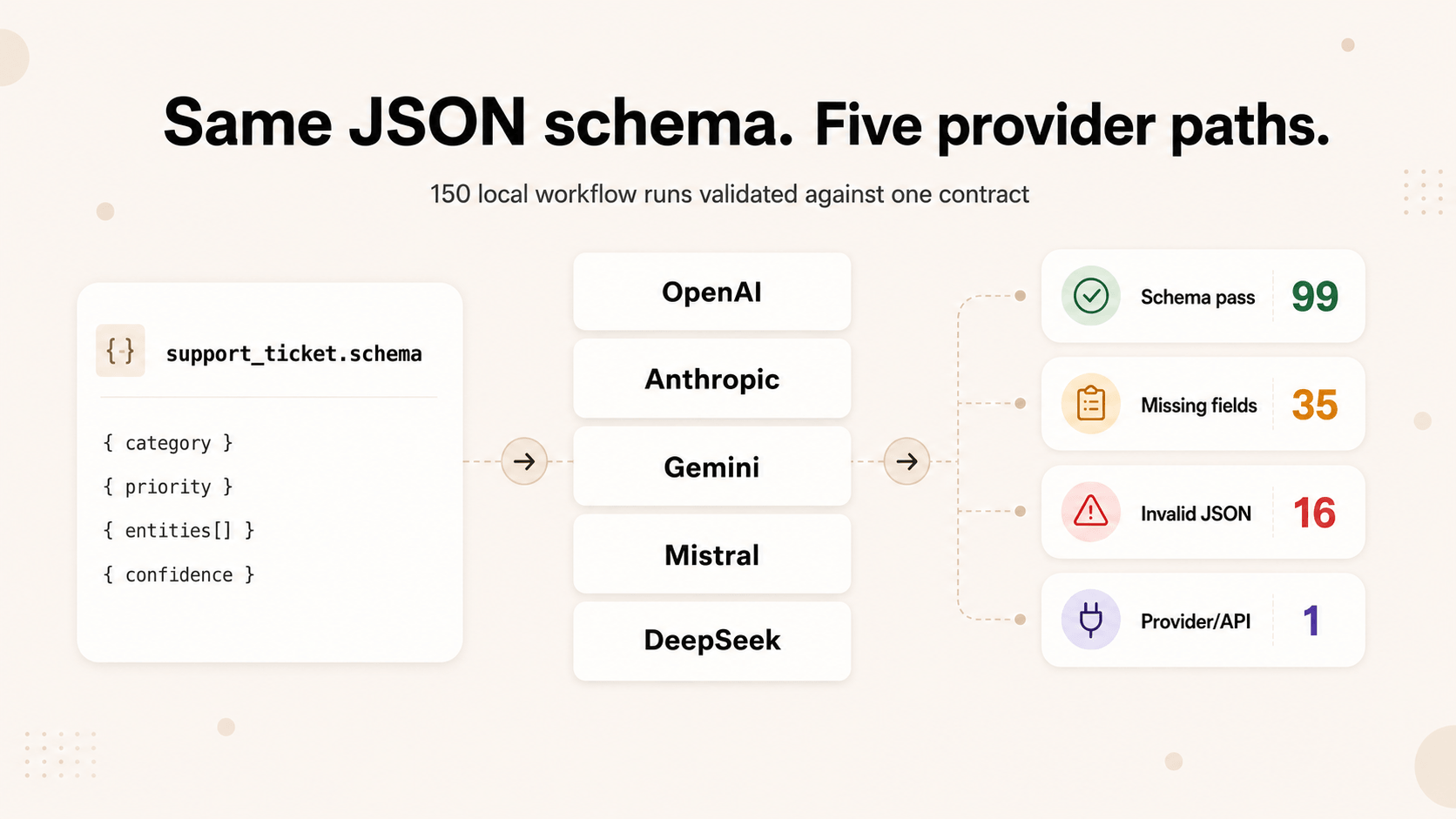
I expected some drift. I did not expect three providers to pass every run while another missed on all thirty.
The test setup was intentionally simple.
We tested five providers:
- OpenAI
- Anthropic
- Google Gemini
- Mistral
- DeepSeek
We used 30 production-like support-ticket prompts that still exercise the kinds of extraction and classification problems AI apps hit in production:
- billing and invoice disputes
- API authentication failures
- sales and pricing questions
- account deletion and data-retention requests
- webhook failures and duplicate deliveries
- structured-output parser bugs
- failover and provider-routing issues
- security, guardrail, and audit-log questions
Each provider received the same task, same structured-output schema, and same validation rules. Every response was checked with the same validator.
This run used local ModelRiver workflows on June 25, 2026 in IST time. That detail matters: this is not a direct vendor-SDK benchmark. It measures what happened when the same ModelRiver structured-output workflow contract was sent through five provider adapters.
That caveat matters most for Gemini. The 0% result below does not mean "Gemini always fails structured outputs." It means this specific schema, prompt set, ModelRiver Google adapter path, model, and validator produced zero strict contract-valid outputs in this run.
| Provider | Workflow | Model | Temperature | Max tokens | Runs |
|---|---|---|---|---|---|
| OpenAI | schema_test_openai | gpt-4.1-mini | 0 | 800 | 30 |
| Anthropic | schema_test_anthropic | claude-sonnet-4-6 | 0 | 800 | 30 |
| Google Gemini | schema_test_gemini | gemini-2.5-flash | 0 | 800 | 30 |
| Mistral AI | schema_test_mistral | mistral-small-latest | 0 | 800 | 30 |
| DeepSeek | schema_test_deepseek | deepseek-v4-flash | 0 | 800 | 30 |
The runner waited 4.5 seconds between requests to stay under the local IP rate limit. The schema, prompts, runner, result CSV, and aggregate summary are in blog/assets/schema-provider-experiment/. Raw provider responses were kept out of the public blog assets because they can contain adapter/debug details that do not belong in a published post.
The schema
We used one schema family rather than a toy example, because toy examples hide most of the failures.
The schema included:
- required strings
- booleans
- numeric confidence scores
- nested objects
- arrays of objects
- enums
additionalProperties: false
Here is a simplified version:
For the final run, we removed numeric minimum and maximum constraints from confidence because Anthropic rejected those keywords in its native structured-output schema. That was a useful reminder by itself: the "same schema" sometimes has to be reduced to the subset every provider path will accept.
This is the kind of schema many teams would consider normal for a production AI feature. It is not exotic. It is just strict enough to catch the gap between "the model returned JSON" and "the application can safely use this response."
Results
| Provider | Strict schema pass rate | Missing fields | Extra fields | Enum drift | Invalid JSON | Provider/API errors |
|---|---|---|---|---|---|---|
| OpenAI | 100% | 0 | 0 | 0 | 0 | 0 |
| Anthropic | 100% | 0 | 0 | 0 | 0 | 0 |
| Google Gemini | 0% | 14 | 12 | 3 | 16 | 1 |
| Mistral AI | 100% | 0 | 0 | 0 | 0 | 0 |
| DeepSeek | 30% | 21 | 12 | 13 | 0 | 0 |
Before anyone screenshots that Gemini row: this is not a universal provider ranking. It is a report from one schema, one prompt set, one validator, one model version, and one ModelRiver adapter path. Swap any of those and the numbers can move.
The secondary columns overlap. One response can be counted as both "missing fields" and "extra fields" if it returned a different object shape altogether.
The headline result was not that one provider was "good" and another was "bad." OpenAI, Anthropic, and Mistral all passed this contract in this run. Gemini did not pass any run: most failures were malformed JSON or a different object contract, with one upstream availability error. DeepSeek passed 9 of 30 runs, but often returned a compact classification object instead of the full application contract.
When Gemini came back at 0%, my first reaction was to blame our adapter. Then I opened the raw responses. Half of them looked like reasonable answers. They just were not the contract we had written down. That mismatch is worse than a clean error — it fails quietly.
That is the part that feels familiar if you have debugged this in production. The bad responses were not always nonsense. Many were reasonable, human-readable answers. They were just not the shape the application promised itself it would receive.
That matters because most application code does not fail on "provider quality." It fails on specific assumptions:
- this field always exists
- this value is always an enum
- this number is really a number
- this object never includes extra keys
- this nested array is always an array
When those assumptions differ by provider, switching models becomes a contract migration, not just a routing change.
What this does not prove
This test does not prove that one provider is always better than another for structured outputs. It only shows that the same application contract can behave differently across provider paths.
Different schemas, prompts, model versions, SDKs, or provider-native structured-output settings may produce very different results. A provider that returned 0% here could pass cleanly with a looser schema, a different model, or its own native structured-output mode. The point is not "this provider is bad." The point is that "the same schema" is not a guarantee you can rely on without testing it.
Failure mode 1: valid JSON, wrong contract
The most common dangerous failure is a response that looks fine in logs but fails your runtime validator.
Gemini returned this for ticket_007:
That is valid JSON. It is also the wrong contract.
The schema required:
The validator error was not subtle:
The model gave a reasonable label. The app asked for a structured object.
Failure mode 2: truncated JSON
Gemini also returned malformed content for ticket_001. This is an excerpt from the wrapped response payload, where the candidate JSON was inside a content string:
This is one of the most frustrating failures because the response starts like JSON. If your integration only logs the first few characters, it looks like the model obeyed. The parser fails later.
I lost an afternoon to one of these once. The log snippet looked compliant. The full payload was truncated halfway through an invoice ID.
In this run Gemini produced invalid JSON 16 times. Several of those were truncated strings. Others were plain-text refusal-style messages where the application expected a JSON object.
Failure mode 3: extra fields and enum drift
DeepSeek returned this for ticket_006:
Again, valid JSON. Also an understandable answer. But the schema did not allow issue or severity, category had to be one of the lower-case enum values, and it still missed required fields like summary, entities, requires_human_review, and confidence.
DeepSeek also drifted outside the enum set on other prompts:
That is not random. It is the model trying to be useful. But application code does not want creative enums. It wants one of the values it was built to handle.
Failure mode 4: provider errors are part of schema reliability
Not every failure was a bad model response. Some failures happened before a usable response came back.
Gemini returned one upstream availability error during the run:
If your app depends on a structured response, provider errors are still contract failures from the application's point of view. The UI or backend expected a typed object and got no object at all.
Why mocked tests miss this
Most teams test structured outputs with fixtures.
That is useful, but it mostly tests your own code. It does not test provider behavior.
Mocked responses rarely include:
- enum drift
nullin required fields- stringified booleans
- arrays collapsed into objects
- prose wrapped around JSON
- provider-specific schema interpretation
- partial responses after retries or timeouts
The test passes because your fixture is better behaved than production.
What actually helps
There is no single magic flag that makes structured outputs production-safe across every provider.
But a few practices help a lot.
Validate every response
Do not stop at JSON.parse.
Parseable JSON only tells you that the response is syntactically valid. It does not tell you whether your application contract was honored.
Use JSON Schema, Zod, Pydantic, Valibot, or whatever validator fits your stack. The important part is that validation happens on every provider response, not just in tests.
Log the raw provider output
When validation fails, you need the original response.
If your logs only show "schema validation failed," you still cannot tell whether the provider omitted a field, changed an enum, returned prose, or reshaped a nested object.
The raw output is what lets you tell the difference between a prompt issue, a provider quirk, and a real application bug.
Track failures by provider and model
Structured-output reliability is not only a provider-level property. It can change by model, prompt, schema complexity, and output length.
Track validation failure rates per provider and model. Otherwise a fallback provider can quietly become the source of broken contracts.
Keep provider quirks out of app code
The tempting fix is to add provider-specific parser branches everywhere.
That works once. Then it spreads.
A cleaner pattern is to keep provider-specific formatting, validation, retries, and normalization behind a thin routing layer. Your product code should consume one contract, not five interpretations of the same contract.
Use deterministic fixtures for CI
Provider calls are expensive, slow, and non-deterministic. Your CI suite should not depend on live LLM behavior for every run.
Use deterministic sample outputs to test your app's integration path. Then run a separate provider-compatibility suite on a schedule or before workflow changes.
That split matters:
- fixtures test your application contract
- provider runs test real model behavior
You need both.
Try the experiment yourself
The prompt set, schema, runner, result CSV, and aggregate summary are available in this repository under:
If you publish this externally, that folder can be moved into a gist or small public repo without changing the experiment structure. Keep raw provider responses private unless every payload has been reviewed and redacted.
The minimum useful version takes about five minutes:
- Pick one structured-output schema from your app.
- Create 10 realistic prompts that represent messy user input.
- Send the same schema and prompts to each provider you rely on.
- Validate every response with the same validator.
- Record the failure shape, not just pass or fail.
If you have already signed up for ModelRiver and never made a real request, this is a good first workflow to try: define the schema, attach it to a workflow, run test-mode fixtures to validate your app contract, then run provider comparisons when your provider keys are connected.
Why we care about this
I keep running into this class of bug in production AI work. That is a big part of why we built ModelRiver.
The hard part was not getting a model to return JSON once. The hard part was keeping a stable contract while switching providers, adding fallbacks, debugging failures, testing workflows, and inspecting what actually came back from the model. The failures that stuck with me were never the loud ones. They were the ones where the response looked close enough that nobody noticed until a customer workflow broke.
Structured outputs are useful. They are also not the end of the problem.
The real production problem is making sure the contract survives the whole path:
That path is where AI apps break.
This is why ModelRiver treats structured outputs as a workflow reliability problem, not just a model-output problem. You should be able to test the same contract across providers, see exactly where it breaks, and keep those provider-specific quirks out of your application code. If you want to run an experiment like this one against your own schema, that is the kind of thing workflows, validation, and provider comparisons are there for.