
那天晚上,我开始不再相信自己的代码
快到午夜了,我盯着两行本不该存在的日志。
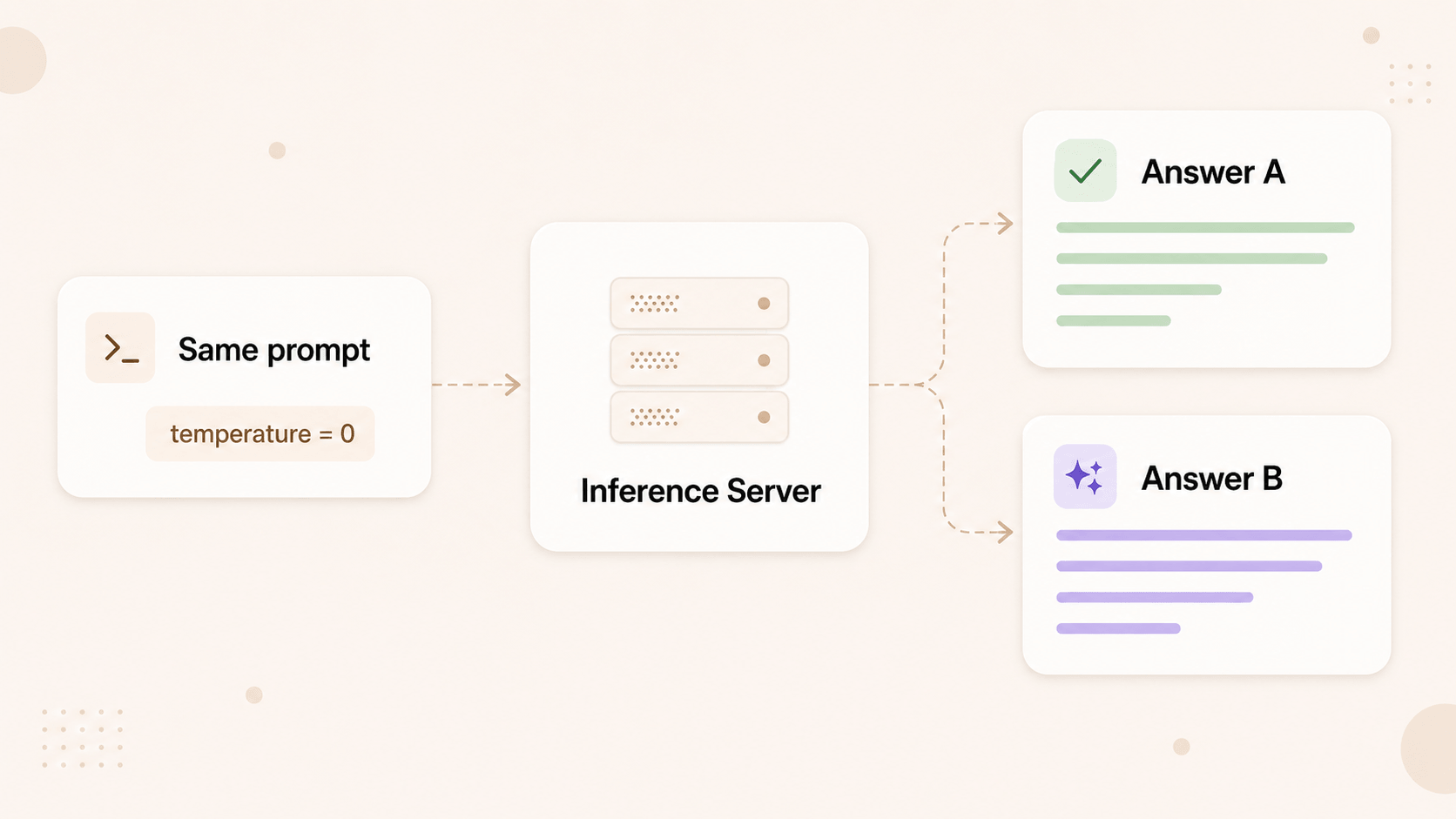
同一个 prompt。同一个模型。同样的参数。temperature 设成了 0——你想让模型别再发挥创造力、老老实实给答案时,就会这么设。两次请求,间隔几分钟。两个不同的响应。
我的第一反应是那个时间点唯一会有的反应:我把什么搞坏了。 于是我做了每个开发者都会做的事,挨个排查最明显的嫌疑对象。是不是我不小心给 prompt 拼上了时间戳?没有。是不是有什么东西在请求发出前改动了它?没有。是不是缓存返回了过期的条目?根本没用缓存。是不是某个重试悄悄打到了另一个模型上?我查了。不是。
我把 prompt 重写了三遍。我在发出去的确切字节周围加了日志。我一个字符一个字符地 diff 了这两个请求。它们完全一致。输入完全一致,输出却不一致,而我没法解释——当你正是那个要为「无法解释的事」负责的人时,这种感觉是真的很糟糕。
如果你在 LLM 之上构建过任何真实的东西,你一定有过这样的夜晚。也许你为此自责了一个星期。我想告诉你我最终弄明白的事,因为我花了太久才搞清楚:有些时候,你追着跑了一整晚的东西,根本不在你的代码里。
我们排查了一切,唯独没怀疑那个最后解释得通的东西
尴尬的地方就在这里。当同一个 prompt 给出不同答案时,模型是我们最后才怀疑的对象。模型感觉像是那个固定不动的点,它周围的一切才显得可疑。
于是我们把它周围的一切都审查了一遍。
- 也许是我们的 prompt 模板不确定。(不是。)
- 也许是 parser 有损,而我们比对的是 parse 之后的输出。(不是。)
- 也许是某个重试包装器悄悄 fallback 到了另一个 provider。(不是——不过这种事确实会发生,值得排除。)
- 也许是两个服务的默认参数有细微差别。(不是。)
我们实打实地花了工程师的时间,把这个症状当成自己系统里的 bug 来治。我理解为什么会这样。我们被教导计算机是确定性的。同样的输入,同样的输出。这个信念太根深蒂固了,以至于它崩塌时,你会假设是你把它弄崩的。
而令人不适的真相是:我们从小相信的那种确定性,在这些模型实际被部署的方式面前根本撑不住。
「temperature 0 就是确定性的」——只可惜它不是
我们先把这个信念说清楚,因为它本身是合理的。
在 temperature = 0 时,采样本应是贪心的:每一步模型都选概率最高的那个 token。采样器里没有随机性。所以原则上,同一个 prompt 应该沿着同样的概率路径走,每次都产生同样的 token。
实践中并非如此。而且这效应一点都不小。
2025 年 Eval4NLP 上的一项研究(Atil 等人,《Non-Determinism of "Deterministic" LLM System Settings in Hosted Environments》)拿了五个基于 API 的 LLM,把它们配置成 provider 所允许的尽可能确定的状态,在八个任务上各跑了十次。让我印象最深的结果是:在同一套「确定性」配置的不同次运行之间,准确率波动高达 15%,最好与最坏的一次运行之间差距高达 70%。没有一个模型能稳定地返回相同的输出或相同的准确率。一个都没有。
再读一遍。同一个模型在同一个任务上两次运行之间的差异,在最坏的情况下,大到足以改变你的功能看起来「能不能用」。
所以如果不是采样器,也不是你的代码,那到底是什么?
这不是「GPU 是并行的」。这个答案是错的。
那个流行的解释——我以前也信、你在大多数走廊闲聊里都会听到的那个——是这样的:「GPU 同时跑成千上万个运算,它们完成的顺序是不确定的,而浮点加法又不完全满足结合律,于是你得到了会改变输出的微小差异。」
听起来很对。这就是并发加浮点假说。Thinking Machines Lab 在一篇叫 Defeating Nondeterminism in LLM Inference 的文章里把它拆开了。他们最后落到的答案更具体、更让人不舒服,也更有用。
事情是这样的:在 GPU 上用同样的输入把同一个矩阵乘法 kernel 跑两次,你通常确实会得到逐位一致的结果。单个 kernel 一般是 run-to-run 确定的。所以并发并不是大家以为的那个层面上的元凶。
在他们的设置里,元凶是一个叫 batch invariance(批次不变性) 的东西——或者更准确地说,是它的缺失。这个限定很重要,因为 hosted API 有太多方式能让你措手不及。但至少这一次,它终于给了我一个具体的形状,去理解那种原本模糊到让人发疯的故障。
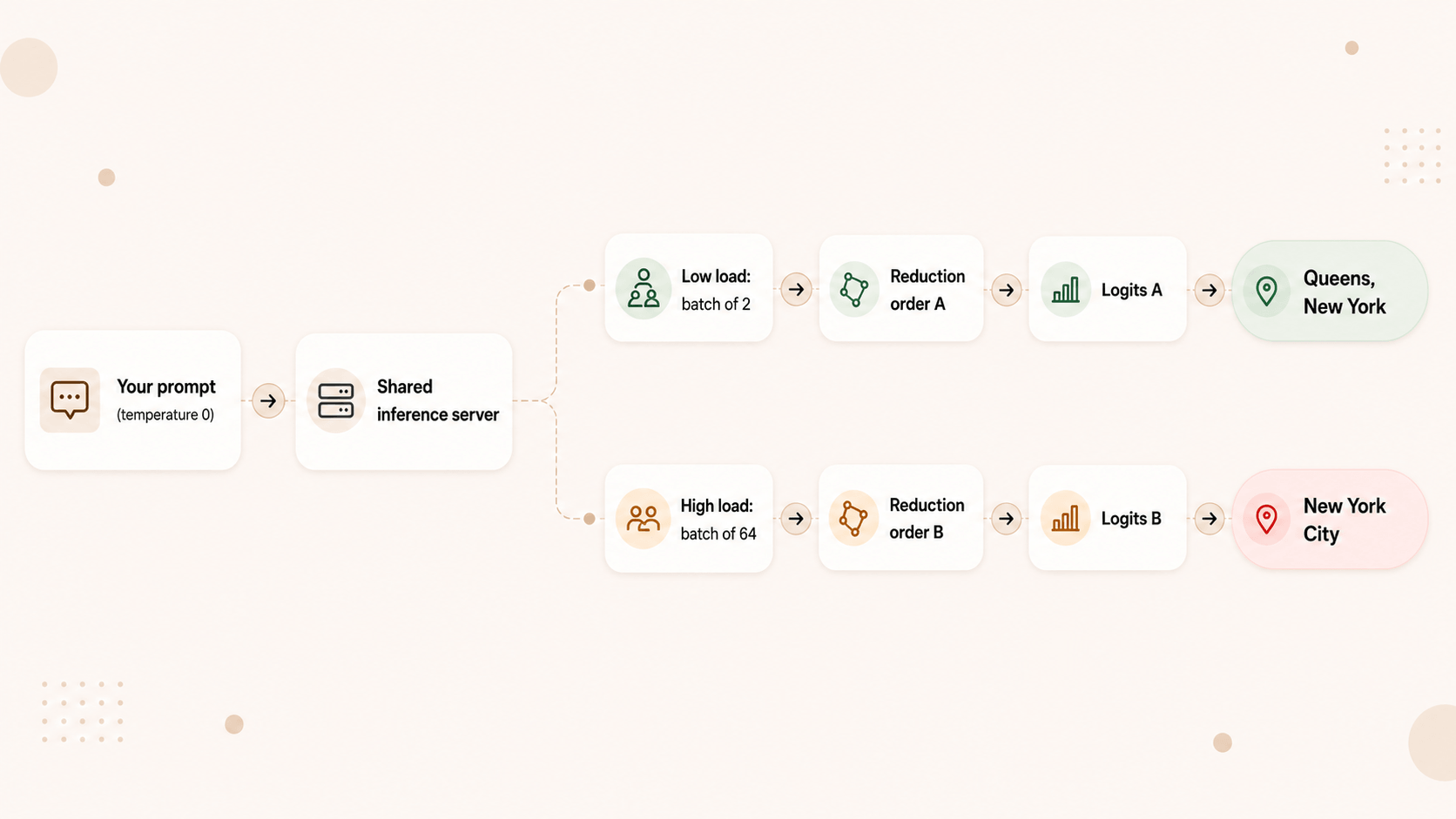
当你的请求打到一台生产推理服务器上时,它不是独自运行的。它会和其他用户的请求被 batch 在一起。负载低的时候,你的 prompt 可能待在一个大小为 2 的 batch 里。负载高的时候,是一个大小为 64 的 batch。这台服务器从它自己的角度看是确定的——给它完全相同的整个 batch,它会返回完全相同的输出。但你单个请求的输出,取决于它恰好落进的那个 batch 的形状,因为 kernel 会根据 batch 大小以不同的顺序去做归约(reduction)。
不同的 batch 大小 → 不同的归约顺序 → 略有不同的 logits → 在两个几乎打平的 token 之间那条刀锋上,被选中的 token 就变了。从那一刻起,两个响应分叉,再也回不到一起。
这部分有点让我脑子转不过来:在这种故障模式里,你的输出可能取决于你提问时服务器有多忙。 不取决于你发了什么,不取决于你的代码,而取决于别人的流量。
Thinking Machines 团队把它做得极其具体。他们在 temperature 0 下让一个模型(Qwen3-235B)「介绍一下理查德·费曼」,跑了一千次。结果得到了一千次里 80 个不同的补全(来源)。每一次运行在前 102 个 token 上都一致,然后在第 103 个 token 处分叉——大多数说他出生在「Queens, New York」,少数说「New York City」。同一个 prompt。同样的 temperature。80 个不同的答案。
然后他们启用了 batch-invariant 的 kernel——一种经过设计、无论 batch 大小都以相同顺序做归约的 kernel——再跑了一遍。一千次里有一千次补全完全一致。 这种不确定性并不是什么自然法则。它只是在变化负载下,那些数学运算具体如何被执行的一个实现细节。
顺便讲讲底下的数学
如果你想要一句话版本的「为什么这事会发生」:浮点加法不满足结合律。一旦涉及有限精度和舍入,(a + b) + c 并不保证等于 a + (b + c)。
这听起来像个舍入误差的脚注。它不是,因为它会层层累积。2025 年的一篇论文 Understanding and Mitigating Numerical Sources of Nondeterminism in LLM Inference(Yuan 等人)表明,当你改变 batch 大小、GPU 数量、甚至 GPU 硬件版本时,输出会发生可测量的变化——即便是同一个 prompt、同一个 seed、同样的贪心解码。他们在一个推理模型上测到:仅仅因为硬件和 batch 大小的变化,准确率波动就高达 9%,响应长度相差多达 9,000 个 token。根因正是这种非结合性,而且这种效应对那些会生成很长思维链的现代推理模型最为严重。每个 token 都以它之前的所有 token 为条件,所以一条长推理轨迹早期的一个微观分叉,到末尾就会级联成一个完全不同的结论。
第七位小数上的一个微小差异,乘以成千上万个顺序生成的 token,就变成了「模型给了个不一样的答案」。就是这样。这就是床底下的那只怪兽。
你可能也会喜欢:我们把同一个 JSON Schema 发给 5 个 LLM Provider,看看哪里会坏
哪怕你冻住了推理,模型也会在你脚下移动
接下来就是它不再是个数值上的小趣闻、而开始成为对你产品的运营威胁的地方了。
假设你解决了上面所有问题。假设你把一切都钉死,今天得到了完美可复现的推理。你仍然有第二个问题,而且它更安静、更阴险:你调用的那个名字背后的模型,可以在不通知你的情况下改变。
像 gpt-4o 或 claude-sonnet-latest 这样的模型名,并不是一个被冻结的产物。它是一个指针。它指向 provider 当前认定为「那个模型」的那个 checkpoint。Provider 会更新这个指针指向的东西——安全调优、成本优化、能力微调、用新数据做的 fine-tuning。这些更新通常在整体上让模型变得更好。它们也可能以一种从来不会出现在 provider 自己 benchmark 上的方式,恰好搞坏你的具体用例。
这不是空想。一项被广泛引用的斯坦福/伯克利研究 How Is ChatGPT's Behavior Changing over Time?(Chen、Zaharia、Zou)对比了 GPT-4 的 2023 年 3 月版和 6 月版,发现在一个判断素数的任务上,准确率从 84.0% 掉到了 51.1%——同一个模型 ID,不同的行为。在那个任务上,平均响应长度从 638 个字符坍缩到不足 4 个。模型没换名字。它只是悄悄变成了一个不同的模型。
而这些失败模式,恰恰是那种能从你的测试眼皮底下溜过去的:
- 拒答风格变了。 一个过去用返回空字符串来拒答的模型,开始返回一段礼貌的话。你的代码写的是
if response == "": handle_refusal()。它再也不会触发了。现在你把拒答当成了有效答案。 - 冗长度漂移。 同一个 prompt 突然返回长了 40% 或短了 60% 的响应。你的延迟 SLA 悄悄破了。你的 token 账单悄悄涨了。
- 被钉死但已废弃的 ID 被静默重映射。 在 Claude Code 的一个已公开报告的案例中,有开发者显式钉住了一个已废弃的 Opus 模型 ID(
--model claude-opus-4-0),CLI 却静默改用了当前的默认 Opus,程序化 JSON 输出里也没有任何 remap 警告。
最后这一条是噩梦场景的微缩版:你做了负责任的事,钉住了一个版本,平台却一声不吭地推翻了你。
你可能也会喜欢:AI Agent 在 Demo 里很容易跑通,难的是在生产中调试它们
为什么偏偏是这一类问题最折磨人
我调试过很多生产事故。这一类格外令人沮丧,我觉得值得说清楚为什么。
普通的 bug 至少有一个堆栈跟踪、一个错误码、一个 500、某个告诉你「看这里」的东西。而这个问题里,你的 dashboard 是绿的。你的请求返回 200。你的 p95 延迟看起来很好。你的 eval——如果你有的话——一直在通过,因为它们是针对那个之后已经漂移掉的行为写的。没有任何告警。唯一表明有东西变了的信号,是一小撮缓慢渗进来的用户投诉,它们感觉像噪声,直到它们不再像。
而真正困扰我的是这一点:你甚至没法提出一个像样的 bug report。「模型有时会给不同的答案」不是任何人能着手处理的工单。没有你自己的证据——你自己记录的、模型过去会做什么 vs 现在会做什么——任何解释都只是猜测。你站在你的团队面前,试图描述一个幽灵。
这就是那个没人会写进 changelog 的情感成本。折磨人的不是失败本身,而是那种无力感。你花在怀疑自己的记忆、自己的代码、自己能力上的那些小时,全都是为了一件从一开始就不在你掌控之内的事。
你实际上能做些什么
你没法从外部让一个托管的 LLM 变得完全确定。但你可以不再被它打个措手不及。目标从「让它变确定」转向「让它可观测」——把可复现性当成一个你去度量的东西,而不是一个你去假设的东西。
下面是真正帮到我们的那套打法,而且它与具体厂商无关。
钉住带日期的快照,而不是别名
如果你的 provider 暴露了带日期的快照(gpt-4o-2024-08-06 这种,或者 Anthropic 的带日期标识符),就用它们。别名按设计就会在你脚下漂移。钉住的快照至少缩小了暴露面——不过要注意,即便是被钉住的模型,它周围的平台级 system prompt 和安全层也可能在演进,所以这是降低风险,不是给出保证。
维护一个冻结的 golden set 并定期重跑
维护一小套有代表性的探针 prompt,配上已知的良好输出。把它冻结。别一直去改它,否则你就失去了跨时间比较的能力。按计划、并在每次 provider 变更时重跑它,与基线做对比。当 golden_v1 突然崩了,说明有某种根本性的东西变了——而现在你手里有的是证据,不是一种感觉。
给行为做指纹,而不只是看通过/失败
跟踪分布,而不只是二元的正确性。有一个便宜又出奇有效的技巧:盯着输出长度的分布(比如拿它和一个滚动基线做对比)。行为漂移往往会在输出的形状上比二元的通过/失败检查更早显现——这正是上面那篇 GPT-4 研究在原始准确率之外,还把冗长度和答案不一致率当作漂移信号来用的原因。
写能容忍漂移的 parser
别再用精确字符串匹配来做控制流。别把行为绑在 response == "" 上。别假设冗长度。校验结构,而不是字节。假设模型的表层行为会移动,把你的代码写得对它健壮。
记录完整的请求生命周期
这一条把所有东西串起来。对每一个请求,你都得能在事后回答:实际是哪个模型、哪个 provider 服务了这个请求,到底发了什么进去,回来了什么,以及它和上周比起来怎么样? 如果你重建不出这些,你就分不清漂移、代码 bug 和一个 batch 凑得不好的倒霉夜晚——你又回到了和幽灵搏斗的状态。
心智模型的转变
那个午夜我多希望有人递给我的结论是:别再把模型当成你系统里那个固定不动的点。 它不是。它是一个远程的、共享的、不断演进的依赖,它的确切行为取决于 provider 的负载、provider 的静默更新,以及你控制不了的浮点数学。
对于其他基础设施,我们很久以前就跟这件事和解了。没人会假设一个第三方 API 永远返回逐字节一致的响应。没人会假设一个数据库不会因为版本升级而改变查询计划。我们给这些东西做埋点。我们留请求日志。我们跨时间 diff 行为。我们为「依赖会移动」这件事做设计。
AI 调用属于同一类依赖——慢、远程、昂贵、且会悄悄变化。那些早早把这一点内化的团队,会停止在午夜责怪自己,转而开始构建那些能在地面移动时察觉到的系统。
我现在之所以能平静地写出这一切,是因为我们最终建起了那天晚上我所没有的可见性。检测不确定性和漂移需要一件不起眼的东西:一份按请求记录的、写明每次调用究竟由哪个模型服务、输入是什么、返回是什么的记录,放在一个你能跨时间比较的地方。这正是我们构建 ModelRiver 想给你的东西的一大部分——请求级的可观测性,这样当同一个 prompt 给出不同答案时,你能看到是什么变了,而不是去怀疑你自己。
你可能也会喜欢:可靠 AI Agent 背后那套隐藏的架构 和 为什么大多数 AI 应用比想象中更早就需要一个 AI Gateway。
你有没有被「同一个 prompt 不同答案」的幽灵坑过?我们在 X 上是 @modelriverai——我是真的很想听听你的故事。