

你上线时选了 GPT-5.5。它跑起来了。你也交付了。
几个月后,新模型出来了。更便宜的,或者更快的,或者你的用户能感受到差异的那种。团队里有人问:"我们能切换吗?"
这个问题的答案,比它听起来要难得多。
不是因为切换模型技术上不可能,而是因为时间久了,你当初选的模型已经渗透进了每个地方。它在你的代码里,在你的 prompt 里,在你的成本估算里,在团队搭产品时做过的每一个假设里。
切换感觉很危险。所以大多数初创公司就一直用最初的那个模型,哪怕更好的选择就摆在那里。
这篇文章讲的就是怎么让这件事不再发生。
AI provider lock-in 的隐藏成本
大多数初创公司一开始都会选择一个 AI provider。通常,这是一个合理的决定。
你要做的是把产品上线,不是搭一套 AI 采购系统。你选 GPT-5.5,把功能做出来,然后继续解决下一个问题。
风险会在后面出现。随着产品增长,最初那个 provider 选择开始影响成本、可靠性、产品速度和 vendor 风险。更好的 OpenAI alternatives 出现了。团队想比较 Claude vs GPT、Gemini vs GPT,或者在某些 workflow 上试试 DeepSeek V4 Flash 和 Kimi K2.6。但工程工作变成了阻碍。
这也叫 AI vendor lock-in。它不只是法律或采购问题。对初创公司来说,它通常表现为产品决策变慢。
很多 SaaS 团队都会遇到这样的时间线:
到了这个阶段,问题就不只是技术问题了。产品实验变慢,AI cost optimization 变难,单一 provider 故障变成业务风险。团队可能知道 multiple AI providers 会有帮助,但 switch AI models 的工作总是被往后推。
这就是 AI provider lock-in。
为什么 AI provider lock-in 会在初创公司发生
第一次给产品加 AI 的时候,你选一个模型,然后快速推进。这是对的。你不想在刚起步的时候花好几周去评估模型。
但这种速度后来会带来一个问题。
通常是这样的:
你在 API 调用里硬编码了 gpt-5.5。你的 prompt 是专门针对 GPT-5.5 的响应方式写的。你的响应解析假设了特定的输出格式。你的成本估算基于 OpenAI 的定价。团队的日志里写的是"调用了 GPT-5.5",仅此而已。
然后新模型来了。Anthropic 发布了 Claude Opus 4.8。Google 推出了更强的 Gemini 模型。DeepSeek V4 Flash 对高频任务来说已经够好。Kimi K2.6 对长上下文任务变得很有吸引力。或者你发现,有一个具体功能,用更小的模型效果其实一样好,成本只有十分之一。
你想试试。但要切换哪怕一个功能,开发者需要:
- 找出所有硬编码模型名称的地方
- 更新 API 调用、错误处理,可能还要换 SDK
- 调整 prompt,因为新模型的响应方式不一样
- 从头开始重新测试这个功能
- 祈祷上线后什么都不会出问题
对于一个本来应该是简单实验的事来说,这工作量太大了。于是团队觉得不值得,继续用 GPT-5.5,又一个季度过去了。
这就是 AI model switching 变成业务问题的方式。不是你计划好的,只是因为切换从来没有被做得容易过。
真正 switch AI models 需要做什么
切换模型不只是改一行字符串。有几件真实的事情需要处理:
模型名称嵌在你的应用代码里。 如果你直接在 API 调用里写 gpt-5.5,每次切换都意味着改代码、做部署。对于快速推进的初创公司来说,这会拖慢产品速度。
不同模型的响应方式不一样。 同一个 prompt,换一个模型,输出可能差很多。你需要在新模型接触真实用户之前先测试它,否则一次省成本的实验可能会变成产品质量问题。
每次切换成本都会变。 单价便宜的模型听起来很好,但如果它需要用两倍的 token 才能说出同样的意思,你最后可能花得更多。你需要真实数据才能做决定。这就是 AI cost optimization 变成产品决策,而不只是工程任务的地方。
你需要一个安全网。 如果新模型宕机了怎么办?或者它突然开始给出更差的结果?你需要 AI failover,否则可靠性就被绑在一个 provider 的稳定性上。
延伸阅读:为什么大多数 AI 应用比想象中更早需要 AI Gateway
现有的工具要继续能用。 如果你的团队用的是 LangChain、LlamaIndex 或者 Vercel AI SDK,你不能为了试一个新 provider 就把所有东西都重写一遍。
这些都不是无解的问题,但都需要被处理,而大多数团队没有一个清晰的系统来做这件事。结果就是实验变慢、vendor 风险增加,multi-model AI 也变得比它本该有的样子更难。
| 传统 AI 集成 | 基于 Workflow 的 AI 集成 |
|---|---|
| 模型名称写在代码里 | 模型在代码之外配置 |
| 切换需要部署 | 切换不需要部署 |
| 很难比较 provider | 很容易比较 provider |
| 有 provider lock-in 风险 | 与 provider 解耦 |
| 手动 failover | 自动 failover |
| 测试困难 | 内置 Test Mode |
更好的思路
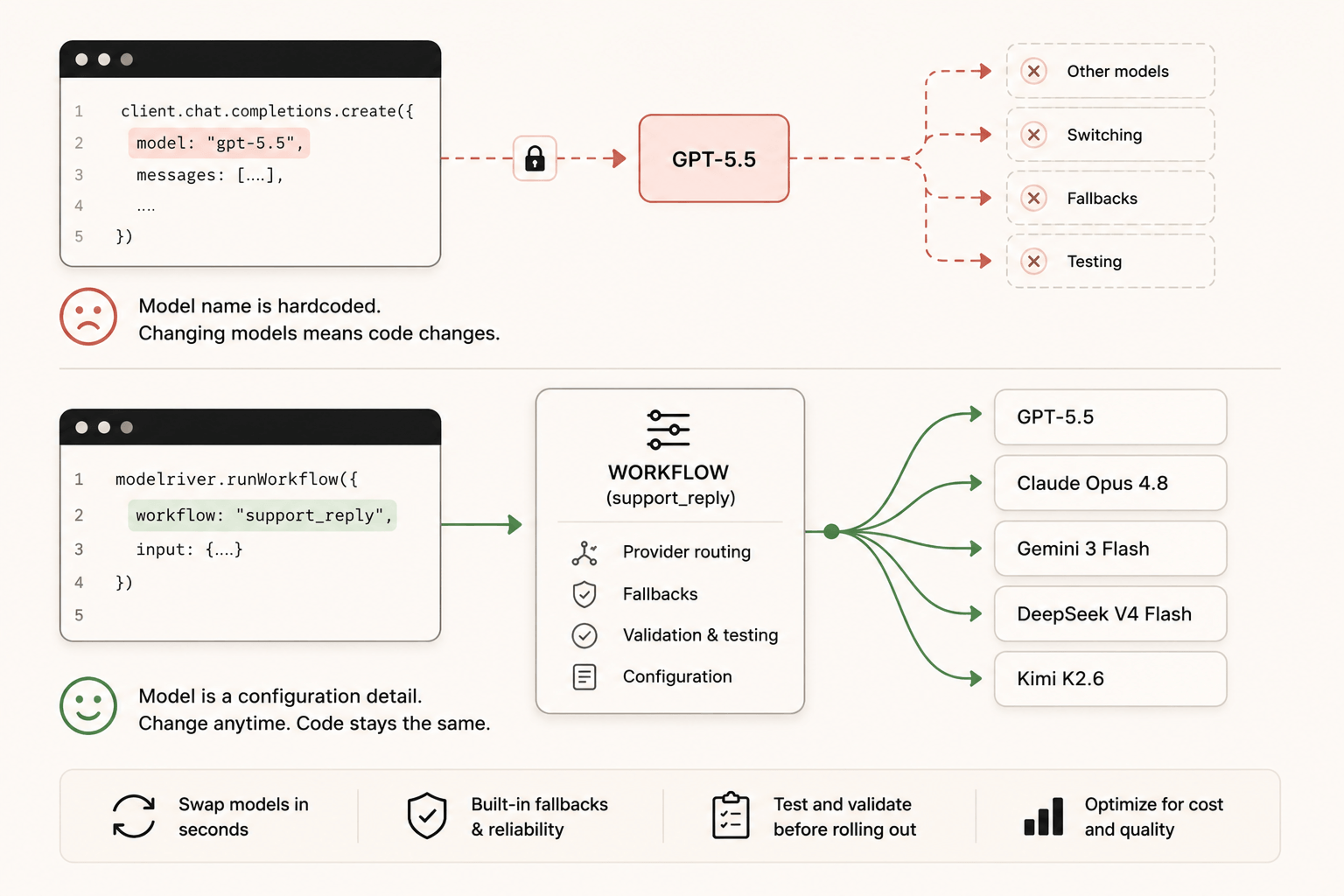
核心问题在于,大多数产品把模型名称当作代码的固定组成部分来构建。解法是把模型和产品解耦。
不要让产品直接调用 gpt-5.5,而是调用像 support_reply、meeting_summary、lead_scoring 这样的名字。这个名字是稳定的,它属于你的产品逻辑。背后用的是哪个模型,是一个住在代码之外的配置细节。
当你想试新模型的时候,你改配置,代码不动,prompt 还是经过测试的,产品继续运转。如果新模型出了问题,你把配置改回去就好了。
这就是 ModelRiver 所说的 workflow。产品里每个 AI 功能对应一个 AI workflow,workflow 里存着所有细节:用哪个 provider、哪个模型、那个模型挂了的备用方案是什么、响应怎么校验。你的产品只需要往 workflow 名字发请求。
这意味着产品团队可以问更好的问题。客服回复应该用 GPT-5.5、Claude Opus 4.8、Gemini 3 Flash、DeepSeek V4 Flash,还是 Kimi K2.6?哪个模型在这个 workflow 上更便宜?哪个更可靠?答案可以来自测试和日志,而不是来自一次代码重写。
ModelRiver 怎么让切换模型变简单
从 dashboard 改模型,不用动代码
当你的 AI 功能都走 ModelRiver workflow 的时候,切换模型就是一个 dashboard 操作。打开那个功能对应的 workflow,选一个不同的 provider 或模型,保存,完成。
不改代码,不做部署,不用担心改一个文件的时候破坏了其他功能。
你的产品团队每次想测试新模型,都不需要拉着开发者一起。这是最直接的实际区别。模型切换变成产品实验,而不是 sprint 计划里的工程任务。
在做决定之前先看清楚成本
切换模型最难的地方之一,就是不知道它到底能不能省钱。便宜的单价听起来不错,但如果一个模型需要更多 token 才能输出同样的内容,你最后可能花得更多。
ModelRiver 追踪每一条请求的成本,按 provider 和模型拆分。你可以看到某个功能用 GPT-5.5 每次请求的成本,然后在同一个功能上试 Claude Opus 4.8、Gemini 3.1 Pro Preview、DeepSeek V4 Flash 或 Kimi K2.6,把真实数字放在一起比较。
这个对比发生在产品内部,用的是你真实的流量,在你做任何永久决定之前。
你能看到这样的数据:
有了这个,你才有真实依据来做决定。你不是在 provider 定价页上猜,而是在比较你自己的 AI workflow 成本。
现有的框架代码继续能用
如果你的团队已经在用 LangChain、LlamaIndex、Haystack 或者 Vercel AI SDK,你不需要改变写 AI 代码的方式。ModelRiver 兼容 OpenAI 接口,所以你只需要改两个地方:base URL 和 API key,其他的都不动。
如果你在用 LangChain:
LlamaIndex、Haystack 和其他框架也是同样的方式。改两个配置值,其他都不动。
如果你想在决定怎么接入之前,先搞清楚哪个框架更适合你的场景,可以看我们的 LLM 框架对比,里面有详细分析。
新模型挂了有备用方案
切换模型不是一次性的决定。模型会宕机,provider 会出故障,高峰期会触发限速。
用 ModelRiver workflow,你在配置 workflow 的时候就设好了备用链。如果主模型失败,请求会自动走到下一个。用户看不到报错,你是从请求日志里知道这件事,而不是从客服工单里知道的。
比如,一个 workflow 可以配置成先试 Gemini 3 Flash,失败了切 Claude Opus 4.8,再失败了切 GPT-5.5。另一个高频 workflow 可以从 DeepSeek V4 Flash 或 Kimi K2.6 开始。这个优先级是根据成本和可靠性数据来决定的,不是靠猜。
不碰生产环境,先测试新模型
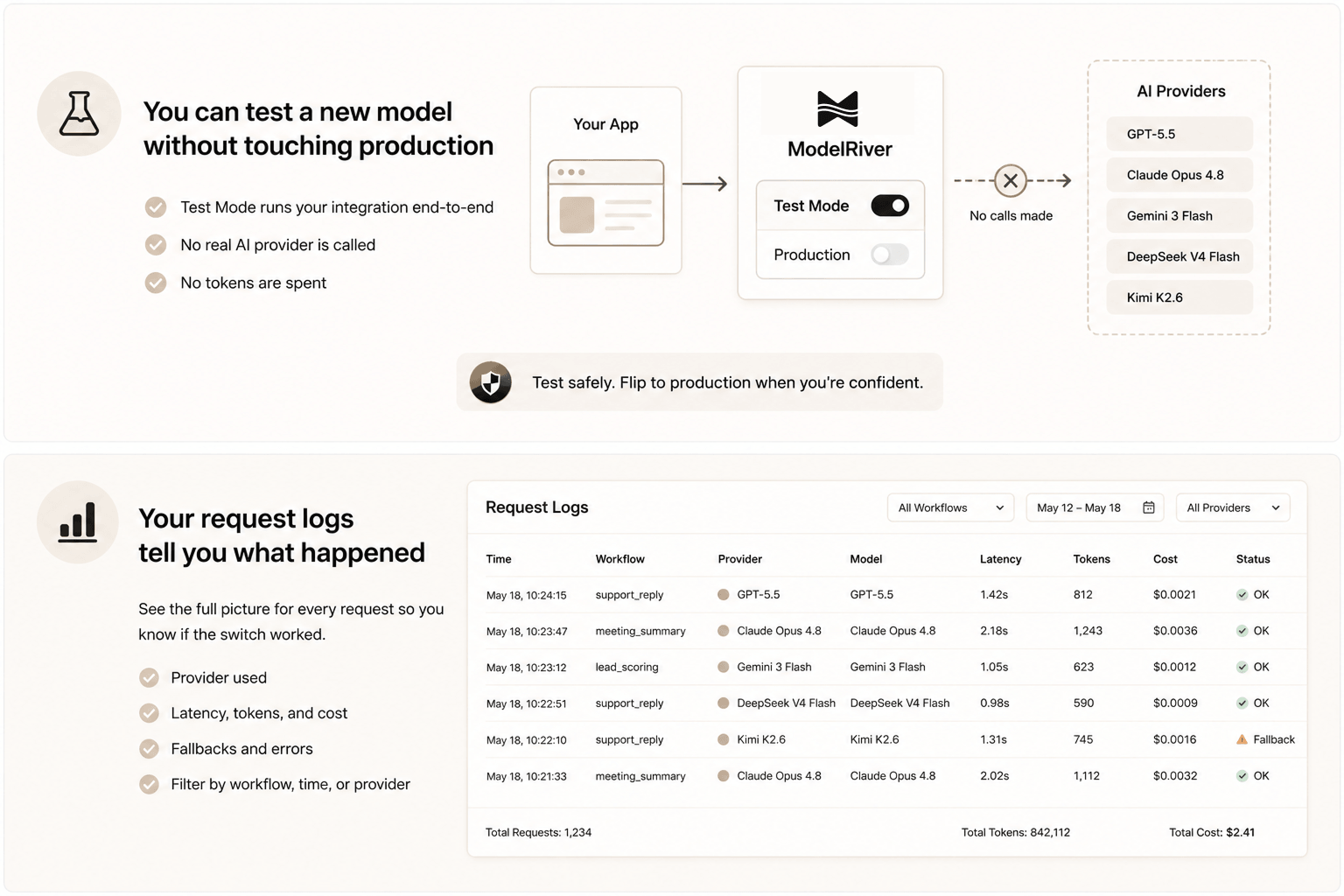
在把任何功能切到新模型上线之前,你可以用 ModelRiver 的 Test Mode 先测试。把 workflow 切到测试模式,定义好一个正常响应应该长什么样,然后跑你的集成测试。你的现有代码会打到真实的 API,走真实的鉴权和日志,但不会真的调用任何 AI provider,也不会消耗 token。
确认集成没问题之后,再把 workflow 切换到生产模式,同时指定新模型。这就是切换这件事。
这消除了切换模型最大的顾虑:在你有机会发现问题之前,就影响到了真实用户。
请求日志告诉你切换之后发生了什么
切换模型之后,你需要知道它有没有真的起效。不只是"功能还在跑",还要知道"质量还好吗,更快了吗,有没有出错?"
ModelRiver 为每一条请求记录完整的时间线。你能看到哪个 provider 服务了这条请求,花了多长时间,用了多少 token,估算成本是多少,有没有触发备用。你可以按 workflow、时间段、provider 筛选。
切换模型之后如果出了问题,你不用靠猜。打开那个功能的请求日志,就能看到发生了什么。这样 AI reliability 就变得可衡量,也更容易向公司里的其他人解释模型选择。
切换 AI 模型的实操清单
用这套方法,整个过程大概是这样:
-
把你的 AI 功能命名为 workflow。 产品里每个功能在 ModelRiver 里都有一个稳定的 workflow 名称,比如
support_reply、onboarding_email、deal_summary,起一个符合你产品语义的名字。 -
让你的代码走 ModelRiver。 改 base URL 和 API key,现有代码继续能用。
-
看清楚你现在的成本。 打开请求日志,看每个 workflow 今天每次请求和总体的成本。
-
为新模型创建一个测试 workflow。 复制现有的 workflow,指向新 provider 和模型,先放进 Test Mode。
-
跑集成测试。 确认响应还是正确的,你的产品处理起来没有问题。
-
切换到生产环境,使用新模型。 把 workflow 切到生产模式,指定新模型,把现在的模型设为备用。
-
观察几天日志。 对比延迟、成本和失败率。如果新模型更好,就留着。如果不行,把备用调回主模型,继续前进。
从第一次测试到放心切换,整个过程可以在一天内完成,不需要任何代码部署。
为什么模型灵活性正在变成竞争优势
AI 模型市场变化非常快。六个月前最好的选择,今天未必还是最好的。新模型不断出来,价格在降,质量在提升。
能快速尝试和切换模型的初创公司,有真实的竞争优势。你可以在便宜的模型够用时削减成本,可以在更好的模型出来时提升质量,可以避免单一 provider 宕机把整个产品拖垮。
那些被一个模型绑住的初创公司,不是因为没有更好的选项。是因为切换从来没有被做得容易过。
解法在原理上很简单:停止硬编码模型名称。给你的 AI 功能起稳定的名字,让这些名字活在配置里,而不是代码里。这样,每个功能背后的模型就变成了随时可以更换、对比和优化的东西。
当切换模型变得容易之后会发生什么?
当切换模型变得容易,团队会开始做出更好的产品决策。
你可以测试一个新的 OpenAI alternative,而不用把它变成迁移项目。你可以比较 Claude vs GPT 的质量,比较 Gemini vs GPT 的速度,或者用 DeepSeek V4 Flash 来评估成本。你可以把 GPT-5.5 用在最看重质量的 workflow 上,把更便宜的模型用在高频任务上。
这会改变初创公司的工作方式:
- 实验速度更快: 产品团队可以尝试新模型,而不用等完整的工程周期。
- AI 成本更低: 当质量足够好时,团队可以把昂贵 workflow 迁移到更便宜的模型。
- vendor 风险更低: 一个 provider 不再控制整个产品的可靠性。
- 可靠性更好: AI failover 可以在 provider 故障时继续处理请求。
- 采用新模型更快: 当 Claude、Gemini、DeepSeek、Kimi 或 OpenAI 发布更好的模型时,你可以很快测试。
真正靠 AI 赢的初创公司,不一定是今天用着最好模型的公司。它们会是明天能最快采用最好模型的公司。
开始使用
如果你现在的情况正是这篇文章说的,迁移过程比你想的要简单:
- 创建 ModelRiver 账号(免费,无需信用卡)
- 添加你的 provider 密钥(OpenAI、Anthropic、Google、Mistral 等)
- 创建第一个 workflow(选一个模型,加一个备用,起一个符合你功能的名字)
- 把 base URL 和 API key 指向 ModelRiver
- 打开请求日志,第一次看到每个功能真实的成本
之后,试一个新模型只是改一个 workflow 设置,不需要改代码。
常见问题
什么是 AI provider lock-in?
AI provider lock-in 指的是你的产品过度依赖某一个 AI provider。模型名称、prompt、错误处理、响应解析和成本假设都和这个 provider 绑在一起。以后仍然可以切换,但需要工程投入,会拖慢业务。
我可以在不重写应用的情况下从 OpenAI 切换到 Claude 吗?
可以。用 workflow 的方式时,你的应用调用的是一个稳定的 workflow 名称,比如 support_reply。workflow 决定这次请求走 GPT-5.5、Claude Opus 4.8、Gemini、DeepSeek,还是其他模型。要从 OpenAI 切到 Claude,你改 workflow 配置,不需要重写应用。
管理 multiple AI providers 的最好方式是什么?
最好的方式是把 provider 选择放在产品代码之外。为每个产品功能使用一个 AI workflow,然后在 workflow 层配置 provider、模型、fallback、测试模式和成本追踪。这样你可以使用多个 AI provider,而不用把 provider 逻辑散落在应用代码里。
我需要重写代码才能用 ModelRiver 吗?
不需要。ModelRiver 使用和 OpenAI 相同的 API 格式。你改两个配置值(base URL 和 API key),现有代码继续能跑。LangChain、LlamaIndex、Vercel AI SDK 以及任何兼容 OpenAI 的 SDK 都不需要修改。
我可以只切换某一个功能的模型,而不影响其他功能吗?
可以。每个功能在 ModelRiver 里有自己的 workflow。改一个 workflow 的模型,只影响那一个功能,其他的完全不动。
我怎么知道新模型是不是更便宜?
ModelRiver 按 provider 和模型追踪每一条请求的成本。在做任何永久决定之前,你可以对比同一个 workflow 在不同模型下的成本数据。
如果新模型宕机了怎么办?
你在配置 workflow 的时候设好备用链。如果主模型失败,请求会自动路由到备用 provider。用户拿到响应,你在请求日志里看到失败记录。
我可以在切换之前先测试新模型吗?
可以。ModelRiver 的 Test Mode 让你在不发起真实 provider 调用、不消耗 token 的情况下验证集成。在把生产流量切换到新模型之前,你可以先确认一切正常。
有关于你具体场景的问题?欢迎在 X 上找我们 @modelriverai。