
The night I stopped trusting my own code
It was almost midnight and I was staring at two log lines that should not have existed.
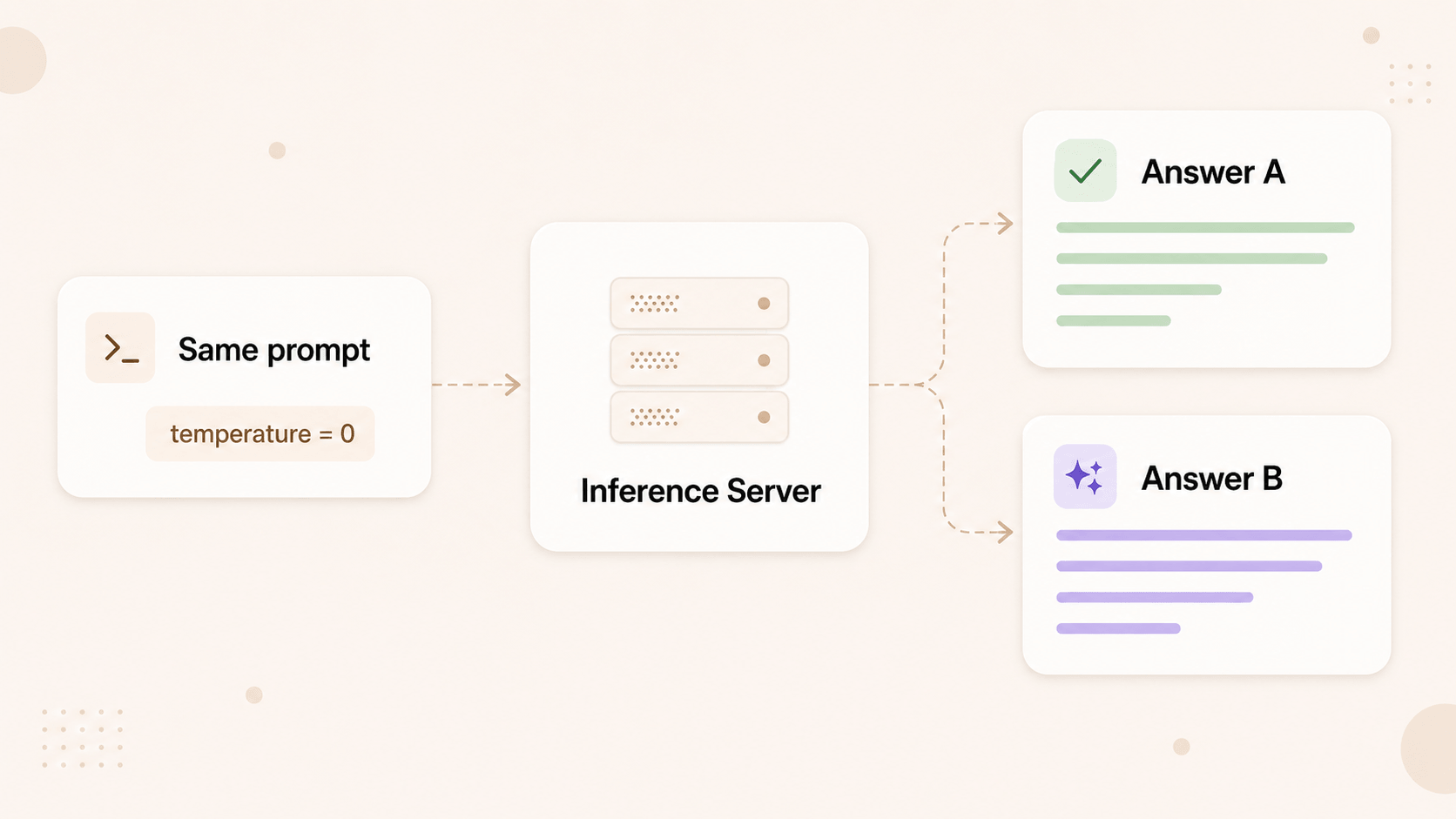
Same prompt. Same model. Same parameters. temperature set to 0, the way you set it when you want the model to stop being creative and just give you the answer. Two requests, a few minutes apart. Two different responses.
My first thought was the only thought I ever have at that hour: I broke something. So I did what every developer does. I checked the obvious suspects. Was I accidentally appending a timestamp to the prompt? No. Was something mutating the request before it went out? No. Was a cache returning a stale entry? No cache involved. Was a retry quietly hitting a different model? I checked. It wasn't.
I rewrote the prompt. Three times. I added logging around the exact bytes being sent. I diffed the two requests character by character. They were identical. The inputs were identical and the outputs were not, and I could not explain it, and that is a genuinely awful feeling when you are the person responsible for the thing being unexplainable.
If you have built anything real on top of an LLM, you have had this night. Maybe you blamed yourself for a week. I want to tell you what I eventually learned, because it took me far too long to find out: sometimes the thing you are chasing is not in your code at all.
We blamed everything except the thing that finally explained it
Here is the embarrassing part. When the same prompt gave us different answers, the model was the last thing we suspected. The model felt like the fixed point. Everything around it felt suspect.
So we audited everything around it.
- Maybe our prompt template was non-deterministic. (It wasn't.)
- Maybe the parser was lossy and we were comparing post-parse output. (It wasn't.)
- Maybe a retry wrapper was silently falling back to a different provider. (It wasn't — though this does happen, and it is worth ruling out.)
- Maybe two services had slightly different default parameters. (They didn't.)
We spent real engineering hours treating the symptom as a bug in our own system. And I understand why. We were taught that computers are deterministic. Same input, same output. That belief is so deep that when it breaks, you assume you broke it.
The uncomfortable truth is that the determinism we grew up with does not survive contact with how these models are actually served.
"Temperature 0 means deterministic" — except it doesn't
Let's be precise about the belief, because it's a reasonable one.
At temperature = 0, sampling is supposed to be greedy: at every step the model picks the single highest-probability token. No randomness in the sampler. So in principle, the same prompt should walk the same path through the probabilities and produce the same tokens every time.
In practice, it doesn't. And it's not a small effect.
A 2025 study presented at Eval4NLP (Atil et al., "Non-Determinism of 'Deterministic' LLM System Settings in Hosted Environments") took five API-based LLMs, configured them to be as deterministic as the providers allow, and ran eight tasks across ten runs each. The result that stuck with me: accuracy varied by up to 15% across runs of the same "deterministic" setup, with a gap of up to 70% between the best-possible and worst-possible run. No model consistently returned the same outputs or the same accuracy. Not one.
Read that again. The variability between two runs of the same model on the same task was, in the worst cases, large enough to change whether your feature looks like it works.
So if it isn't the sampler, and it isn't your code, what is it?
It's not "GPUs are parallel." That answer is wrong.
The popular explanation — the one I believed, the one you'll hear in most hallway conversations — goes like this: "GPUs run thousands of operations concurrently, the order in which they finish is nondeterministic, floating-point addition isn't perfectly associative, so you get tiny differences that change the output."
It sounds right. It's the concurrency plus floating point hypothesis. And the team at Thinking Machines Lab took it apart in a piece called Defeating Nondeterminism in LLM Inference. The answer they landed on was more specific, more uncomfortable, and much more useful.
Here's the thing: run the same matrix multiplication kernel twice on a GPU with the same inputs, and you usually do get bit-identical results. The individual kernels are typically run-to-run deterministic. So concurrency isn't the culprit at the level people assume.
In their setup, the culprit was something called batch invariance — or rather, the lack of it. That distinction matters, because hosted APIs have plenty of ways to surprise you. But this one finally gave me a concrete shape for a failure that had felt maddeningly vague.
When your request hits a production inference server, it doesn't run alone. It gets batched together with other users' requests. Under low load, your prompt might sit in a batch of two. Under heavy load, a batch of sixty-four. The server is deterministic from its own point of view — give it the exact same full batch and it returns the exact same output. But your individual request's output depends on the shape of the batch it happened to land in, because the kernels reduce numbers in a different order depending on batch size.
Different batch size → different reduction order → slightly different logits → and at the razor's edge between two near-tied tokens, a different token gets picked. From there the two responses diverge and never come back.
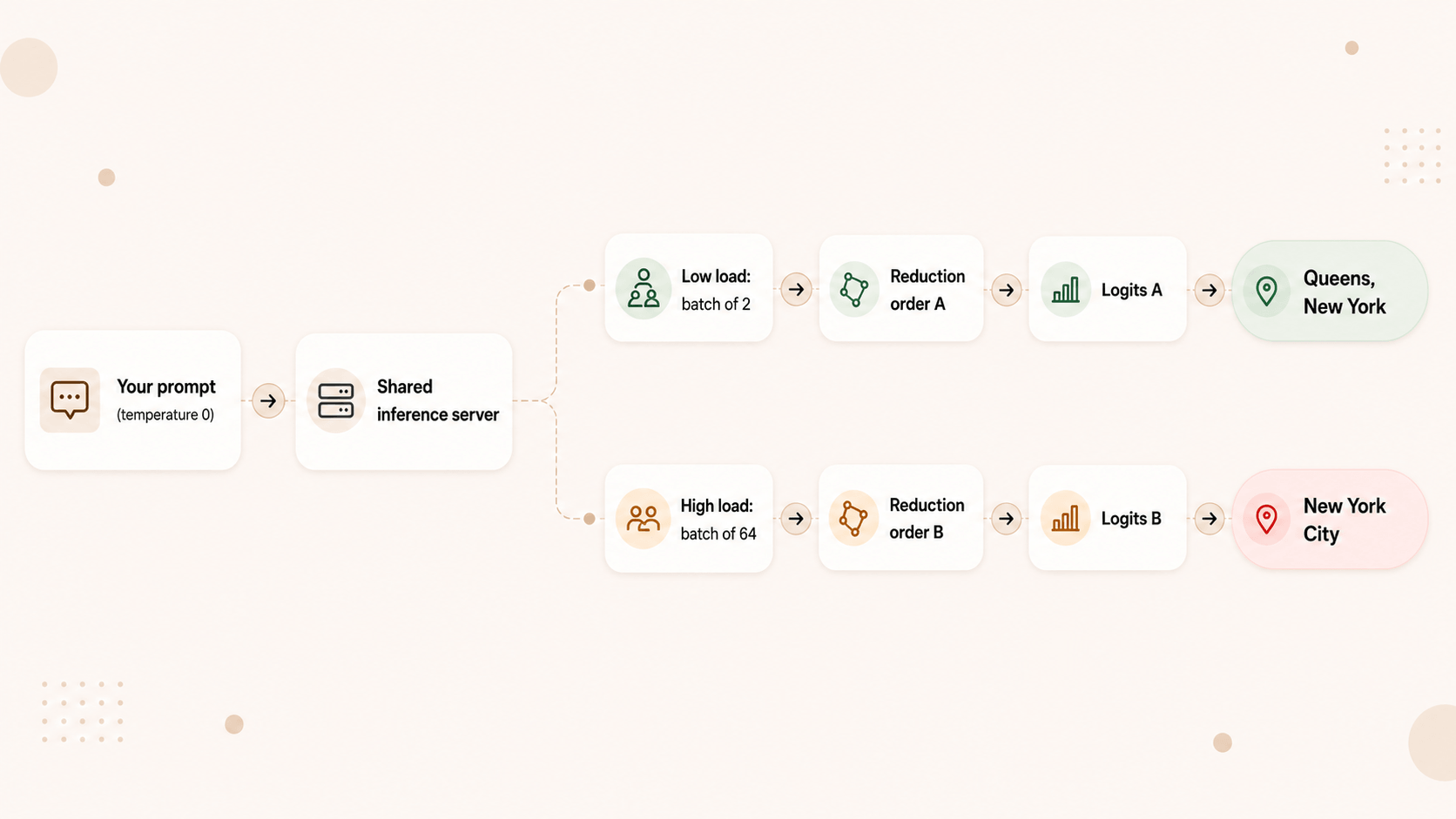
This is the part that broke my brain a little: in this failure mode, your output can depend on how busy the server was when you asked. Not on anything you sent. Not on your code. On other people's traffic.
The Thinking Machines team made it painfully concrete. They asked a model (Qwen3-235B) to "Tell me about Richard Feynman" at temperature 0, one thousand times. They got eighty unique completions out of a thousand runs (source). Every run agreed on the first 102 tokens, then diverged at token 103 — most saying he was born in "Queens, New York," a handful saying "New York City." Same prompt. Same temperature. Eighty different answers.
Then they enabled batch-invariant kernels — kernels engineered to reduce in the same order regardless of batch size — and ran it again. One thousand identical completions out of one thousand. The nondeterminism wasn't a law of nature. It was an implementation detail of how the math was being done under varying load.
The math underneath, briefly
If you want the one-sentence version of why this happens at all: floating-point addition is not associative. (a + b) + c is not guaranteed to equal a + (b + c) once you involve finite precision and rounding.
That sounds like a rounding-error footnote. It isn't, because of how it compounds. A 2025 paper, Understanding and Mitigating Numerical Sources of Nondeterminism in LLM Inference (Yuan et al.), showed that outputs change measurably when you vary the batch size, the number of GPUs, or even the GPU hardware version — same prompt, same seed, same greedy decoding. They measured up to 9% accuracy variation and a 9,000-token difference in response length on a reasoning model, purely from hardware and batch-size changes. The root cause is exactly that non-associativity, and the effect is worst for modern reasoning models that generate very long chains of thought. Each token is conditioned on every token before it, so a microscopic divergence early in a long reasoning trace cascades into a completely different conclusion by the end.
A tiny difference in the seventh decimal place, multiplied across thousands of sequential tokens, becomes "the model gave a different answer." That's it. That's the monster under the bed.
You might also like: We Sent the Same JSON Schema to 5 LLM Providers. Here's What Broke.
Even if you freeze the inference, the model still moves under you
Here's where it stops being a numerical curiosity and starts being an operational threat to your product.
Suppose you solved all of the above. Suppose you pinned everything and got perfectly reproducible inference today. You still have a second problem, and it's quieter and meaner: the model behind the name you call can change without telling you.
A model name like gpt-4o or claude-sonnet-latest is not a frozen artifact. It's a pointer. It resolves to whatever checkpoint the provider currently considers "that model." Providers update what the pointer resolves to — safety tuning, cost optimizations, capability tweaks, fine-tuning on new data. These updates usually improve the model in aggregate. They can also break your specific use case in ways that never show up in the provider's own benchmarks.
This isn't hypothetical. A widely-cited Stanford/Berkeley study, How Is ChatGPT's Behavior Changing over Time? (Chen, Zaharia, and Zou), compared the March and June 2023 versions of GPT-4 and found accuracy on a prime-number task dropping from 84.0% to 51.1% — same model ID, different behavior. On that task, average response length collapsed from 638 characters to under 4. The model didn't get a new name. It just quietly became a different model.
And the failure modes are the kind that slip right past your tests:
- Refusal style changes. A model that used to decline by returning an empty string starts returning a polite paragraph. Your code does
if response == "": handle_refusal(). It never fires again. Now you're treating refusals as valid answers. - Verbosity drift. The same prompt suddenly returns responses 40% longer or 60% shorter. Your latency SLA quietly breaks. Your token bill quietly climbs.
- Pinned-but-deprecated IDs get silently remapped. In one reported Claude Code case, a developer pinned a deprecated Opus model ID (
--model claude-opus-4-0) and the CLI silently served the current default Opus instead — with no remap warning in the programmatic JSON output.
That last one is the nightmare scenario in miniature: you did the responsible thing, you pinned a version, and the platform overrode you without a word.
You might also like: AI Agents Are Easy to Demo. Debugging Them in Production Is the Hard Part
Why this one really messes with your head
I've debugged a lot of production incidents. This class is uniquely demoralizing, and I think it's worth naming why.
With a normal bug, there's a stack trace, an error code, a 500, something that says "look here." With this, your dashboards are green. Your requests return 200. Your p95 latency looks fine. Your evals — if you have them — keep passing, because they were written against behavior that has since drifted. There is no alarm. The only signal that something changed is a slow trickle of user complaints that feel like noise until they don't.
And here's the part that genuinely bothered me: you can't even file a coherent bug report. "The model gives different answers sometimes" is not a ticket anyone can act on. Without your own evidence — your own record of what the model used to do versus what it does now — any explanation is just speculation. You're standing in front of your team trying to describe a ghost.
That's the emotional cost nobody puts in the changelog. It's not the failure. It's the helplessness. The hours you spend doubting your own memory, your own code, your own competence, for something that was never in your control to begin with.
What you can actually do about it
You can't make a hosted LLM perfectly deterministic from the outside. But you can stop being ambushed by it. The goal shifts from "make it deterministic" to "make it observable" — treat reproducibility as something you measure, not something you assume.
Here's the playbook that actually helped us, and it's vendor-neutral.
Pin dated snapshots, not aliases
If your provider exposes dated snapshots (gpt-4o-2024-08-06-style, or Anthropic's dated identifiers), use them. Aliases drift under you by design. A pinned snapshot at least narrows the surface — though be aware that even pinned models can have platform-level system prompts and safety layers evolving around them, so it's a reduction in risk, not a guarantee.
Keep a frozen golden set and re-run it on a schedule
Maintain a small set of representative probe prompts with known-good outputs. Freeze it. Don't keep editing it, or you lose the ability to compare across time. Re-run it on a schedule and on every provider change, and compare against the baseline. When golden_v1 suddenly tanks, something fundamental shifted — and now you have evidence instead of a feeling.
Fingerprint behavior, don't just check pass/fail
Track distributions, not just binary correctness. A cheap and surprisingly effective technique is watching the distribution of output lengths (e.g. comparing it against a rolling baseline). Behavioral drift often shows up in the shape of the outputs earlier than it shows up in binary pass/fail checks — which is exactly why the GPT-4 study above used verbosity and answer-mismatch as drift signals alongside raw accuracy.
Write parsers that tolerate drift
Stop matching exact strings for control flow. Don't key behavior off response == "". Don't assume verbosity. Validate structure, not bytes. Assume the model's surface behavior will move and make your code robust to it.
Log the full request lifecycle
This is the one that ties it all together. For every request you need to be able to answer, after the fact: which model and provider actually served this, what exactly was sent, what came back, and how does that compare to last week? If you can't reconstruct that, you can't tell drift from a code bug from a bad night of batching — and you're back to debugging a ghost.
The mental model shift
The lesson I wish someone had handed me that midnight: stop treating the model as the fixed point of your system. It isn't. It's a remote, shared, evolving dependency whose exact behavior depends on the provider's load, the provider's silent updates, and floating-point math you don't control.
We made peace with this for other infrastructure a long time ago. Nobody assumes a third-party API returns byte-identical responses forever. Nobody assumes a database is immune to version upgrades changing query plans. We instrument those things. We keep request logs. We diff behavior over time. We design for the dependency to move.
AI calls are the same class of dependency — slow, remote, expensive, and quietly mutable. The teams that internalize this early stop blaming themselves at midnight and start building systems that notice when the ground shifts.
The reason I can write any of this calmly now is that we eventually built the visibility I didn't have on that first night. Detecting nondeterminism and drift requires one unglamorous thing: a per-request record of exactly which model served each call, what went in, and what came back, in one place you can compare over time. That's a big part of what we built ModelRiver to give you — request-level observability so that when the same prompt gives a different answer, you can see what changed instead of doubting yourself.
You might also like: The Hidden Architecture Behind Reliable AI Agents and Why Most AI Apps Need an AI Gateway Sooner Than They Think.
Have you been burned by the same-prompt-different-answer ghost? We're @modelriverai on X — I'd genuinely like to hear your story.